《现代操作系统》的读书笔记,这里记录了进程间通信和互斥的问题。
进程
进程可以简单地理解为正在运行的程序。一般程序是指编译为二进制文本的文件(如C语言),或者有特定程序去解释执行的文件(如Python),而进程就是操作系统将程序调入内存中运行之后的状态。
进程的创建
一般有四个情况会导致进程创建:
- 系统初始化时:这个时候系统自己会创建一些进程
- 一个现有的进程执行了创建进程的系统调用:比如在C/S模型架构的服务器中fork子进程
- 用户要求创建进程:比如你双击了程序图标
- 初始化了一系列作业(一般在批处理系统中)
存在在后台的进程被称为守护进程(daemon)。在Unix下,系统启动时创建的第一个进程为init进程,随后的所有进程都是其子进程。由此构成了一个进程树。而Windows下进程之间没有任何的关系,不存在进程层级。
在Unix下,新创建的进程(采用fork函数)会和其父进程共享一份数据,直到其父进程或其本身改变了这份共享的数据,这时,会将共享的数据拷贝一份给子进程。这种做法叫写时复制(Copy On Write)。
进程的销毁
有如下四种情况导致进程销毁:
- 进程正常退出:这个时候进程该做的事情都做完了,于是正常瑞出。
- 错误退出:由于程序发现了一个致命错误(fatal error)而导致的退出,但是这个错误是可以被程序控制的(比如C语言编译器编译了不存在的文件)。
- 致命错误:进程产生了一个致命错误,这个是进程没有预料的错误,比如访问了不存在的内存地址。
- 被其他进程杀死:比如Linux下使用kill命令杀死进程
前两种都是进程自愿退出型。后两种是非自愿退出型。
进程状态
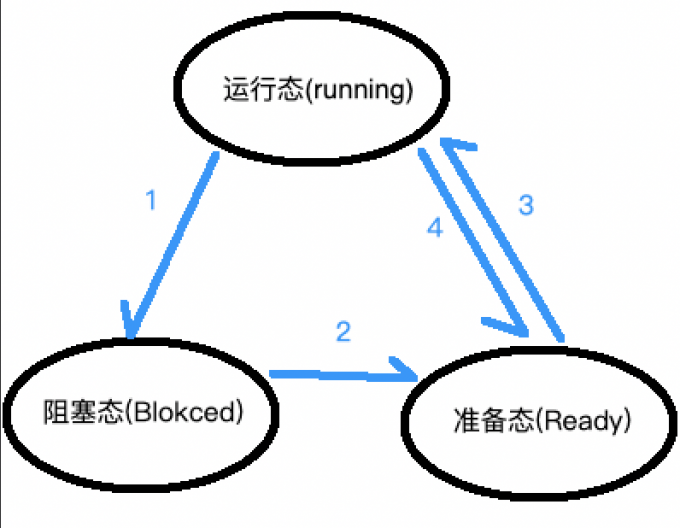
进程有三种状态:
- 运行态:这个时候进程正在运行
- 阻塞态:这个时候进程被IO阻塞
- 准备态:进程准备运行
阻塞态和准备态的区别:
阻塞态是进程在运行的时候,由于IO阻塞或者系统调用引起的。比如C++代码cin<<a;等待用户输入时就是阻塞态。
而准备态则是进程时间片用完了,CPU将其换下来的状态,是由CPU而不是IO阻塞引起的。
这三种状态的转换为:
- 运行态到阻塞态:正在运行的程序由于IO阻塞,或者系统发现他现在没办法运行(比如调用了
pause()函数或者sleep()函数,就会将其切到阻塞态。 - 阻塞态到准备态:当从IO阻塞恢复,或者可以运行(
sleep()函数的事件到了或者在pause()中用户按下了按键)时,CPU并不会直接让其运行,而是先放入准备态等待运行(等待属于其的时间片到来才能运行) - 准备态到运行态:进程调度算法准许此进程运行,这时进程就从准备态到运行态
- 运行态到准备态:进程的CPU时间片用完了,进入准备态等待下次运行。
准备态不可能到阻塞态,因为在准备的进程不能执行代码,所以不可能调用阻塞系统调用或者IO函数。
进程间通信(IPC)问题
进程间通信被称为IPC(InterProcess Communicate),由于进程间通信而带来的问题就叫做IPC问题。
IPC总共有三大类问题:
- 进程间如何传递消息?
- 进程之间如何不产生竞争条件?
- 进程取资源的顺序
进程间传递消息的话,在Linux下可以使用共享内存和共享文件,或者管道,Socket套接字。总之这个问题已经有很多解决方法了,也不是讨论的重点。
重点是后面两个问题,本质上都是由于时间片轮转造成的。竞争条件(race condition)是指
当多个进程都企图对共享数据进行某种处理,而最后的结果又取决于进程运行的顺序时,我们认为发生了竞争条件
——《Unix环境高级编程》
《现代操作系统》中举了个例子:
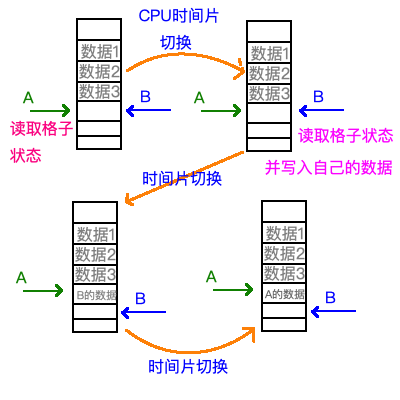
假设A和B程序的功能都是“在内存中找到下一个空闲区域并放入自己的数据”。首先A读取格子状态,发现其是空的,准备写入数据;这个时候,A的时间片用完了,操作系统让A进入准备态,让B进入运行态。然后B读取了当前格子的状态,写入了自己的数据,并且移动到下一格准备重复上述操作。这个时候,B的时间片到了,B进入准备态,A进入运行态,代码从A离开的那句开始执行。由于A先前判断当前格子是空的,所以会写入自己的数据,这样B的数据就被覆盖了,产生了bug。
临界区(critical regions)
为了解决竞争问题,提出了临界区的概念:
临界区指的是一个访问共用资源的程序片段,而这些共用资源又无法同时被多个线程访问的特性。当有线程进入临界区段时,其他线程或是进程必须等待
——百度百科
也就是说临界区就是那段要共享的数据区。在每一时刻只能由一个进程进入临界区(访问共享数据)。为了更好的解决竞争,光有临界区还不够,这里首先提出四个条件:
- 没有任意两个进程在同一个临界区内
- 不对CPU的数量和速度做假设
- 临界区外的进程不能阻塞其他进程
- 没有进程需要无止境地等待进入临界区
在这四个条件下来研究解决竞争问题的方法。
一次只能由一个进程进入临界区的情况称为互斥(mutul exclusion)
忙等待下的互斥
首先考虑使用忙等待来实现互斥。
关闭中断法
因为CPU切换线程是通过时钟中断的信号来切换的。时钟中断会以一定时间给出一个中断,比如5ns。假设分配给每个进程的时间片都一样,是15ns,那么当时钟中断发生3次就CPU就会切换一个进程。
所以如果将中断关闭的话就不会切换进程,那样进程就可以完成自己的工作了(比如上面A不仅可以读出格子信息,还能写进去)。
这是一个防范,但是这个风险非常大。因为中断对于操作系统来说是非常重要的东西,一般在0环实现(内核中),所以将中断的开闭权限给用户的话(3环,用户层)对系统是非常不利的,比如你的程序在关闭中断之后忘记打开了,那CPU就不能切换进程了。所以这个方法被否决
锁变量法
让一个变量L为锁,初值为0.当有进程要进入临界区的时候,让L为1表示现在临界区里面有进程了。其他进程看到L=1就等待。当进程出临界区时将L设为0以允许其他进程进入。
这个方法也是治标不治本,因为和上面的竞争例子一样,假设A查看L得知为0,想要进入临界区时CPU切换进程B,B查看L发现为0,设为1后进入临界区。然后CPU切换为A,A再次将L设为1,然后进入临界区。所以这个方法没什么卵用。
严格轮换法
在变量锁上进一步改进得到自旋锁:
| |
turn作为锁变量(称为自旋锁),记录着当前进入临界区的进程。每一个进程自己有一个ID(这里假设A的ID是0,B的ID是1,并且turn的初值为0,代表允许A先进临界区)。每个进程在进入临界区之前需要判断turn是否为自己的ID,如果为自己的ID则进入。在离开临界区之后将turn赋值为下一个进程的ID。
这里就算A在判断trun是否为0的时候切换到了B,B也会由于turn=0而无法进入临界区,有效地避免了竞争。
但是这个算法是不行的,不说B因为忙等待不停地测试turn变量带来的CPU浪费,当A执行完临界区的工作和非临界区的工作后,返回带循环开头第4行,但这个时候B还第20行做非临界区相关工作。那么A就被阻塞不能进入临界区了。这就违反了上面所说的条件3:“临界区外的进程不能阻塞其他进程”。所以这个也不行。
Peterson的解决办法
| |
现在只考虑有两个线程的情况。turn是用于标志想要进入临界区进程的自旋锁,intersted则是表示已经进入临界区的进程数组。假设A现在调用了enter_critical_region(0),这时interested[0]=1,interested[1]=0,turn=1。A通过第十行的判断,进入临界区。就算在第九行被切换为B进程,B也会因为interested[other]==1`的条件而忙等待。
Peterson的方法是忙等待算法中唯一一个没有什么缺点的算法。
TSL指令带来的CPU间互斥
要注意到在多核CPU中,各个CPU之间的进程可以真正意义上同时执行,那么当然也会产生竞争条件。这个避免方法是采用汇编指令TSL,现在的CPU一般都带有这个指令:
| |
他将内存中LOCK变量的值读入寄存器RX中,并且设置LOCK的值为非0值。需要注意的是**这两部操作是一个原子操作,原子操作就是不可被分割的操作。也就是说在执行TSL指令时CPU不能切换。**那么这个时候就可以写出临界区代码:
| |
enter过程从LOCK中取出其值放入AX中,并且同时将LOCK设为1.然后看AX是否为0,为0表示可以进入临界区,程序返回。为1表示不行,于是回到enter标号中重新执行。也就是说当LOCK值为0时表示临界区现在无进程。
TSL是的实现不是关闭中断,因为你关闭了一个CPU的中断和另一个CPU没什么关系。它关闭的是CPU到内存的内存总线。
这个没什么算法可言,主要是硬件指令帮了忙。
唤醒和睡眠下的互斥
忙等待下的互斥主要是通过让进程忙等待来等待进入临界区,但是这样显然太浪费CPU。我们可以通过将进程变为阻塞态来等待进入临界区(因为阻塞态是不消耗CPU的,只有相关信号到达CPU才会调用进程,其他时候CPU不会分配给进程时间片)。
一般操作系统有sleep()和wakeup()函数。sleep用于让当前进程进入阻塞态,而wakeup指定将一个通过sleep进入阻塞态的进程进入到准备态。在这个情况下,我们可以用sleep和wakeup函数来改善Peterson的方法了。
Linux下sleep对应wait()函数,而wakeup对应poll()函数。
生产者消费者问题
这是一个经典的IPC问题。问题描述如下:
假设现在有一个共享的固定大小的缓冲区。生产者进程(记为P)的任务是向缓冲区中空白的部分放置数据,而消费者进程(记为C)的任务是从缓冲区中拿取已有数据。如何调节这两个进程?
首先想到可以先让生产者生产,消费者睡眠,当生产者生产完后唤醒消费者,自己进入睡眠。消费者如法炮制,将缓冲区消费之后唤醒生产者,自己进入睡眠。具体的代码如下:
| |
这里显然有一个不足之处,就是两个进程都能对count变量无约束地访问。这就导致如下的竞争条件:
消费者运行到第16行读取了count,假设此时count为0,然后CPU切到生产者,生产者执行完代码,在第10行唤醒了消费者,然后再次循环到第8行进入睡眠。此时CPU切到消费者,消费者由于之前确认了count为0(实际上此时已经为1),进入睡眠。这样,双方都进入睡眠,程序死循环。
解决这个问题的一个方法是记录下生产者消费者收到的唤醒,然后在进入睡眠时查看记录。如果存在唤醒记录就不睡眠。但是这样就需要为每一个生产者消费者提供一个额外变量,很占用内存。
信号量(Semaphore)
为了解决生产者消费者问题,Dijkstra(没错就是搞图论算法的那位)提出了至今都在使用的信号量(Semaphore)。
信号量的思想融合了锁变量和原子操作:
信号量为一个特殊的整型变量,其值为0(表示没有保存唤醒操作)或者正数(有一个或者多个唤醒操作)。对其的操作有两个:
- Up操作:又称为V操作,会将信号量的值加1。如果存在睡眠的进程,就唤醒那个进程让其完成其Down操作。
- Down操作:又被称为P操作,会先判断信号量是否为0,如果为0,让这个进程睡眠。如果大于0,将其减1.
并且Up和Down操作是原子操作。
所以Down操作和Up其实是这样的:
| |
这里有一点要注意:如果现在s是0,那么当进行一个Up操作之后,虽然将s加1了,但是被唤醒的进程会立刻将s减1,所以在信号量为0的时候并且有沉睡进程时,对其进行Up操作不会改变信号量的值(为0)。
一般来说实现UP和DOWN的方法是将其作为系统调用,然后在执行时暂时关闭中断。
互斥量(Mutex)
如果不需要信号量的计数功能,信号量会简化为互斥量。这个学过多线程编程的都知道,我就不细说了。
管程
使用过互斥量或者信号量的同学应该知道,如果其解锁代码的位置发生了变化,会带来完全不一样的结果。由于信号量和互斥量使用的复杂性,人们提出了管程。管程其实是编程语言概念,是语言内部带有的。C语言就没有,但是Java就有。管程就相当于一个好用的库。
消息传递
其实消息传递问题在计算机网络中有很多解法。操作系统里面的方法和计算机网络的差不多,就不一一介绍了。这里主要是说如何用消息传递解决生产者消费者问题。
我们不用缓冲区进行物品存放,而是采用**信箱📪**的方法。消费者首先传输N个空信封给生产者,生产者接收到空信封之后就往里面填充数据,然后返回信封给消费者。消费者拿出来消费之后再将空信封传给生产者。当有一方没有信封时进入睡眠,直到信封到来。这种算法的好处是没有用到任何的中间缓冲池。
屏障(Barrier)
这个是为进程组设计的。在多进程程序设计中,尤其是大矩阵分解运算的时候,每个进程都在计算自己的数据,等到所有数据都算好之后再整合为结果矩阵。这时可以用屏障,即当其中一个进程算完后会被屏障阻拦,不能够继续下面的操作,而必须等待直到所有进程完成计算,再一同进行下一次操作。
一些典型的IPC问题
哲学家就餐问题
现在有五个哲学家坐在圆形餐桌上,他们就干两件事情:吃饭和思考人生。每个人右手边都有一支筷子,要吃饭的时候必须拿起其左右两边各一支才能吃饭。那么如何协调这些哲学家?
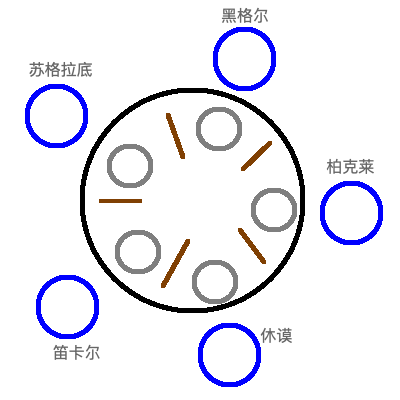
这里的问题在于,如果一个哲学家要开始吃饭,他得先拿起左边筷子再拿起右边筷子。如果其中有一个筷子被人拿了,那哲学家就没有办法吃饭。
首先可以采用靠运气的方法:每个哲学家想要吃饭时拿起两个筷子。如果其中有一个筷子被拿起来了,那么就将他拿起的筷子放下,然后等待一段随机时间再吃饭。这种算法的思想类似于计算机网络中避免链路拥塞的方法。但是在需要快速反应的RTOS和交互式系统中,这也许不是最好的办法。
其实解决这个问题很简单,有多线程编程经验的同学应该可以看出来:这里有五个公共的资源——五支筷子,造成竞争条件的原因是因为对筷子的拿起没有约束。所以我们可以对每个筷子加一个信号量(或者互斥锁随便),当哲学家想要吃饭时,先看自己手边筷子齐不齐。不齐的话就不吃饭,齐的话就给筷子上锁,然后拿起筷子吃饭,吃完放下筷子再解锁。这样就解决问题了。
读者写者问题
这个问题广泛用在机票订购等系统中。说的是现在有一群读者和写者需要访问一块资源。读者只读数据,写者只改变数据。那么如何协调?
这个问题和哲学家问题以及生产者消费者不一样,因为读者对信息的读取是没有破坏性的,所以可以允许多个读者同时读。但是写者一次性只能有一个。所以我们可以使用先来先服务策略,如果来的是读者,那么直接进入读取数据。但是如果是写者,必须等待临界区中的所有读者读完之后再进入临界区,并且在其后的读者也不允许比他先进临界区。
其实这个算法可以做一个小小的改进:如果写者到来了,将资源拷贝一份,让临界区内的读者读取拷贝的资源,写者则改变原有资源。这样写者就不用等待读者离开临界区了。但是这很占内存。
进程调度算法
CPU一次只能运行一个进程的代码。如果想要实现多进程,就必须使用进程调度算法。
线程有两种类型:
- IO密集型(I/O-bound):这种进程的大多时间花在IO操作上(比如终端系统)
- 计算密集型(compute-bound):这种进程将大多时间花在计算上
随着现代CPU运行的越来越快,程序越来越趋向于IO密集型。
何时调度进程:
- 创建进程的时候。是优先运行父进程还是子进程
- 在进程退出时。这时CPU必须切换到下一个进程
- 当进程阻塞在IO或信号量或其他事情上。这个时候也需要切换进程
- IO中断发生时。这个时候IO的操作完成了,算法必须决定是否切换到等待这个操作的进程
由于有三种不同类型的操作系统(批处理系统,交互式系统,实时操作系统),所以每个操作系统上的算法目标也不一样:
- 共同目标
- 公平:给每个进程公平的CPU份额
- 策略强制执行:进程不能违背调度算法
- 平衡:尽可能让系统各部分忙碌(充分利用CPU和外设)
- 批处理系统:
- 吞吐量:单位时间内完成的作业数
- 周转时间:从提交作业到作业终止的时间(不是作业运行到终止的时间)
- CPU利用率
- 交互式系统:
- 响应时间:响应用户操作的时间
- 均衡性:满足用户的期望
- 实时操作系统
- 满足截止时间:避免丢失数据
- 可预测性
进程调度算法在大体上分为两种:
- 抢占式调度:每个进程运行一段时间,到了规定时间后不管有没有运行完,都切换到另一个进程。
- 非抢占式调度:进程运行的图中CPU不会切换其他进程,除非进程自己放弃运行,否则进程必须运行完才能切换进程。
批处理系统下的调度算法
批处理系统会接收到一堆称为作业的程序,然后运行他们即可。像很久以前的打孔式机器就是批处理。批处理不提供交互功能,只需要完成到来的作业即可。
先来先服务(first-come first-serve)
首先可以想到让作业排队,先到来的作业先运行,运行完之后再运行下一个作业。这是非抢占式算法。
最短作业优先
这种算法需要实现知道作业大概的运行时间,然后当存在一批作业到来时,按时间递增的顺序依次运行作业。这也是非抢占式算法。
这里要注意的是,一批作业必须同时到来,如果A作业在B后面到来,那么即使A的时间比B的短,B程序也不能停下转换到A程序,因为这个算法是非抢占式的。
这个算法主要是让平均周转时间最短。假设现在有一批程序同时提交给系统:
程序 时间
A 5
B 6
C 2
D 1
如果按照先来先服务,周转时间为:
程序 周转时间
A 5
B 5+6=11
C 5+6+2=13
D 5+6+2+1=14
那么平均周转时间约为$\frac{5+11+13+14}{4}=10.7$。
如果按照最短作业优先:
程序 周转时间
D 1
C 3
A 8
B 14
平均周转时间为6.5,显然是缩小了。
最短剩余时间优先
这个算法是最低按作业优先的抢占式版本。也就是说不管新作业什么时候来,只要新作业的时间比老作业的剩余时间少,CPU就切换到新作业执行。
交互式系统下的调度算法
交互式系统是我们用的最多的系统,包括Mac,Windows和Linux系统等。特点是注重和用户的交互,所以响应时间显得尤其重要。交互系统总是采用抢占式算法
轮转调度
很简单,将进程排成环,CPU给每一个进程分配同样的时间片,时间到了就换下一个进程执行。
这个算法对时间片长短有要求。因为如果时间片过短,会因为平凡的切换进程导致的存储进程信息时间变长。比如时间片为10ms,但是切换一个进程需要1ms,那这显然很浪费CPU。但是时间片过长的话,系统响应用户的速度将会变慢。所以需要合理选择时间片。
优先级调度
在轮转调度的基础上发展而来,进程之间不再平等,而是具有优先级。优先级高的进程先被执行,而且只要存在优先级高的进程,就不会去执行优先级底的进程:
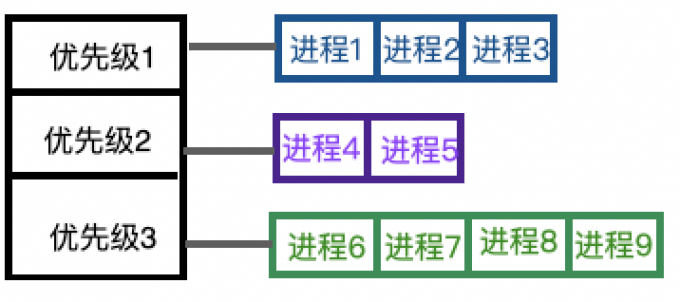
这个算法存在一个缺点:如果高优先级的进程源源不断地到来,那么低优先级进程将无法被执行,这种情况叫做饥饿。
多级反馈队列
Unix系统采用的方法,在优先级调度上发展起来的算法。同样也是将进程分优先级。但是高优先级的时间片较少,低优先级的时间片较多。而且每个队列的算法可以是不一样的。低优先级的队列可以采用时间片轮转方法,而高优先级队列则采用先来先服务算法。并且还可以通过用户操控改变优先级:比如用户在终端按下了回车键,那么位于优先级3的终端程序会被提升到优先级1,以快速地和用户交互。
最短进程优先
这个是从批处理系统上借鉴来的。如果有多个进程同时执行的话,我们可以先执行执行时间最短的那个,这样系统的反馈速度会加快。比如你先打开了一个Word软件,然后在其加载的时候又打开了Vim。系统知道Vim的打开时间会比Word短,那么即使Word先打开的,也会运行Vim。
这里唯一的问题是如何估计进程的事件。在批处理系统中每个作业是重复运行的,所以有较大的把握知道作业的运行时间。但是交互式进程只能猜测:假设某一程序上次运行时间为$T_1$,这次时间为T_2,那么我们可以通过$aT_1+(1-a)T_2$的方式来猜测下次的事件。这里a是老化参数。如果a取0.5的话,那么三轮的猜测时间为
$$
T_1,\frac{1}{2}T_1+\frac{1}{2}T_2,\frac{1}{4}T_1+\frac{1}{4}T_2+\frac{1}{2}T_3
$$
这样先前测量的值会随着时间逐渐减小,这种情况叫做老化。
保证调度
保证调度为了公平性,如果进程没有优先级的话,保证每个进程运行的时长都尽可能一样。也就是说,如果A进程比B进程先开5小时(并且目前没有结束),那么算法会在后续的运行中多分配B进程时间片,直到弥补B进程少的5小时。
这个算法也可以用在多用户系统中,保证每个用户的运行时间一致。
这样系统必须跟踪进程来记录下其运行的总时间。
彩票调度
这是一种基于概率的(靠运气的)调度方法。系统给每个进程分配彩票,然后等到要调度的时候,从已分配出去的彩票中选择一个,拥有这个彩票的进程呗执行。
如果某个进程需要更多的CPU时间话,可以分配给其更多的彩票来让其更可能被运行。
公平分享调度
这是对于多用户系统而言的算法。每个用户都获得等同的CPU时间片(而不管用户内部的调度程序怎么使用),让每个用户的调度时间公平。
实时系统(RTOS)中的调度
实时系统是指需要对外界反映做出快速响应,并且能快速完成任务的系统。一般而言都是嵌入式系统。比如汽车搭载的系统,当刹车时系统必须及时反映并允许刹车程序。或者是工业机器人中搭载的系统。也就是说正确但是迟到的答案比没有更糟糕。