《现代操作系统》的笔记。这里记录了段和页的相关知识。
实模式和保护模式
首先必须说明一下实模式和保护模式。在“汇编语言”课程中,包括王爽的《汇编语言》中,大家接触到的都是16位汇编。16位汇编的特点是寄存器是16位的,并且对于内存的访问是任意的。
但是任意对内存访问的话很容易导致内存混乱和,尤其是当存在操作系统的时候,如果能够对内存进行随意的访问,可能会更改操作系统所在的内存。也就是说,在16位模式下,没有任何的内存模型,当时的内存分布有三种:
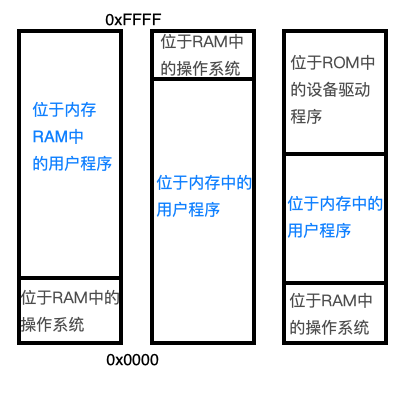
最右边的情况虽然说稳定一点,但是操作系统还是有可能被修改。16位下的对内存无限制访问的情况称为实模式。
很快32位和64位的CPU发展了出来,Intel公司意识到,如果像这样不给内存读写加上任何限制的话,程序的编写还得是一个难事,所以给CPU加上了保护模式。保护模式中你需要告诉CPU自己的程序用到哪些段,段的起始地址和大小。如果你访问了不在段内的内存,CPU会产生异常中断。
在16位下,虽然寄存器是16位的,但是地址总线是20位的,为了更好地利用内存,采用了段地址*16+偏移地址的做法来寻址20位内存,也就是$2^{20}=1MB$。所以16位寄存器20位总线只能寻址1MB内存,内存多了也没用。
到了32位,由于地址总线都32位了,就取消了段地址*16+偏移地址的做法,直接将段地址和偏移地址相加得到内存地址。这个时候寄存器可以寻址$2^{32}=4GB$内存,所以在32位机器上安装4GB内存就够了,多了CPU也用不了。
64位的话显然可以使用$2^{64}=2^{24}TB=16777216TB$,这下用户再也不愁内存太多CPU用不了了。
在保护模式下,由于内存寻址突然变大了,可加载的程序也变多了,各个程序之间的内存协调也越来越重要,于是Intel公司在其处理器上又退出了分页机制。所以说分页机制只能在保护模式下使用,实模式下是不能使用的。
IntelCPU下的计算机在启动的时候,为了兼容以前的程序,首先进入的还是实模式。这个时候就算你有32位总线你还是只能使用20位。一般操作系统都会有引导程序,引导会采用Intel规定的方法从实模式跳转到保护模式,然后在保护模式下加载和运行操作系统。所以你一开机就可以使用32位和64位的程序。但是如果你自己写操作系统就还得考虑从实模式到保护模式的事情。
段
分段机制在汇编语言课程中有所涉及,这里不再赘述。简单来说就是讲程序分为很多的段,每一段负责不同的数据或者代码。在Unix操作系统中,一般有四个典型的段:
- .text段:用于存储代码
- .data段:用于存储已经初始化的数据
- .bss段:用于存储没有初始化的数据
- 栈 段:用于当做栈
段与段之间可以不是连续的,比如如下实模式代码:
| |
而保护模式下,可以通过告诉CPU段首地址来找到段,所以段也可以是不连续的。
在高级语言中,编译器帮你隐藏了段的概念。程序在编译之后(如gcc)产生的文件里会存在段的信息。通过查看可以发现段也不一定是连续的(这部分知识见操作系统-4-文件系统)。
接下来具体看一下保护模式下如何使用段(以NASM汇编器为例):
32位保护模式下使用段
首先得看一下这个图:
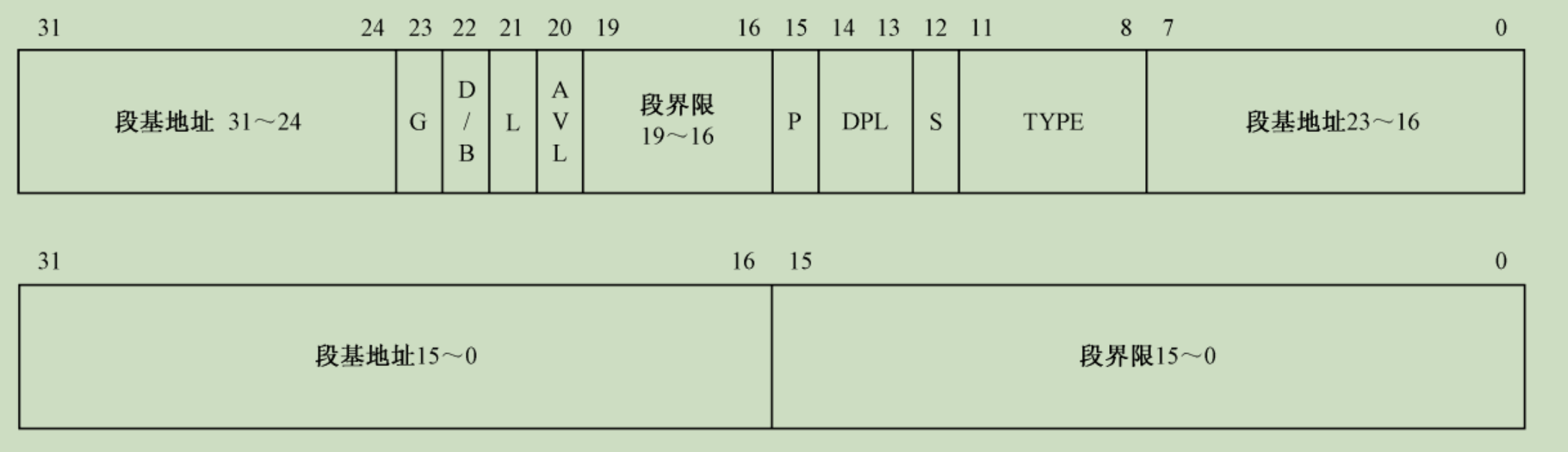
这个表示GDT(Global Description Table全局描述符表)的内存结构,GDT有64字节,里面分别存放了段的信息,还有一种LDT和GDT的功能和格式是一样的,只不过一般用在用户程序中(GDT用在操作系统程序中)。接下来对其中的信息做一下说明:
- 段界限:这个段的长度,用20个字节表示。可能有人会问为什么这个段界限不放在一起,高4位和低16位分开了。这个是由于Intel在推出最初拥有保护模式的80386CPU之前尝试推出过80286CPU,80286是在16位情况下使用保护模式,其中段界限就是放在AVL字段和P字段之间的,但是80286不给力,被淘汰了,所以80386为了兼容就搞成这样了,段基地址的分离也是这个原因。
- 段及地址:段的首地址,32位长度
- TYPE:标志这个段的类型,是数据段?代码段?可读的?不可读的?依附的?一共占4位
- S:代表这个段是不是系统使用的,占1位。有些段是系统使用的,比如指向LDT表的段
- DPL:三个位表示的优先级,由于只有三位,所以只能表示三个优先级。0优先级最高,一般是内核运行的优先级。1优先级其次,一般是驱动程序所在优先级,2优先级最低,用户程序所在。低优先级的代码不能访问高优先级的段。
- P:这个段目前在不在内存中。占1位。如果不在而去访问,会产生
缺页中断,一般配合分页机制使用 - AVL:没卵用位,程序员可以自定义用途
- L:从16位保护模式遗留下来的,如果为0表示使用16位保护模式,现在都是32和64位保护模式,应该一直置1
- D/B:也是16位保护模式遗留下来的,表示汇编指令中的操作数大小。为0表示操作数视为16位的,为1表示32位的。现在都是置1
- G:表示段界限的粒度。为0表示Byte,为1表示KB。也就是说,假如段界限是$0xA3=163$,G为0表示163字节,而G为1表示163KB。
引导程序在进入会先设置自己的代码,数据,栈段,然后从实模式跳入保护模式,加载操作系统程序,然后将程序控制权交给操作系统。操作系统开始运行时,一般会首先重新设置GDT以便寻址更大的空间(因为引导程序一开始在实模式下工作,只能寻址1MB内存,所以GDT所指向的段大小加起来最大不能超过1MB。而进入保护模式之后可以寻址4GB,所以操作系统要重新设置GDT)。下面是使用NASM编写的一个小引导程序:
| |
让我来简单解释一下:
第1行%include是NASM汇编器的预编译指令,和C的#include一样,包含一个文件进来。pm.inc中存在一些常量定义和GDT_ITEM宏,用于快速生成一个GDT表项(就是上面图中的那个东西)。
第2行使用一个段内近转移。因为CPU在执行的时候是从上往下执行的,但是这个语句下面有GDT表,GDT表是数据不能被执行的,所以需要使用这个跳转语句跳转到24行的代码主体。
4和5行定义了常量,表示栈的位置和大小(equ是NASM定义常量的关键字),栈我们不放在这个程序里面。
第3行的[bits 16]表示下面的代码汇编为16位的,直到52行的[bits 32]改为汇编为32位。
然后是8到13行的GDT表的构建,里面构建了CODE32_SEG32位代码段,CODE32_STACK_SEG32位栈段,CODE32_DATA_SEG32位数据段(在第55行的段),VIDEO_SEG显存段(用于向屏幕显示文字)。这里9行的dq 0是声明一个64位的空GDT项,Intel规定GDT的前64位必须为0。
我们有了GDT表了,但是CPU怎么知道它的大小和位置呢?第15行定义了40位的GDT描述符,分别记录了GDT的大小和首项的内存位置。
19到22行定义了GDT选择子,这个后面会说道。
然后程序来到了代码主体,进入24行的代码段。这个时候还在16位实模式,而这个代码段的功能就是打开保护模式并跳转到保护模式的代码段。25到36行是填充CODE32_SEG和CODE32_DATA_SEGGDT项的段基地址。可以看到我们在定义的时候给了0(GDT_ITEM后的第一个参数),所以现在要填充(不在声明的时候填充是因为NASM的限制)。
39行通过lgdt [GDTR_ADDR]的指令将含有GDT信息的GDT描述符的地址给专用的GDTR(GDT Register)寄存器。这个时候CPU就可以通过GDTR寄存器找到GDT表了。
41到43行打开A20总线开关。这个是历史原因。因为一开始CPU进入的是16位嘛,但是我们电脑有32位总线啊,那你在16位总线上工作这几个指令
| |
那你说最后找到的数据段地址是什么?,显然得溢出对吧。但是总线有32位,意味着这个运算是会成功的。为了在16位下正常运行,Intel在第21根总线上动了手脚,让其在第21根线的值恒为0,这样在32位下就可以和16位一样运行16位代码了。但是进了32位后就不需要这个功能了。这里的代码就是关闭这个功能。
然后45行关闭中断。因为保护模式下的中断机制和实模式下也不一样,所以关闭实模式中断。
47行到49行是真正进入保护模式的代码:只需要将特殊寄存器cr0的最低位置1就可以开启保护模式了(顺便说一句,将其最高位置1会开启分页机制,所以分页机制默认不是开启的。一般都在操作系统代码里开启)。到这里我们就进入保护模式了。
虽然进入了保护模式,但是我们的代码还是在16位下,所以51行一个段间远转移跳到32位的保护模式代码段(60行)(其实不仅为了进入32位代码,也是为了刷新指令流水线)。这里注意跳转命令的写法:
| |
在保护模式下由于每个段都在GDT表中注册过了,所以就不用直接指定段的地址进行跳转了,而是需要指定段选择子。这里CODE32_SELECTOR在第19行有定义,值为$0x08$。计算方法是将这个值向右移3位,得到的结果是段在GDT中的位置。这里右移后是$0x01 = 1$,即在GDT表中的第一个位置(11行的声明,第一个空表项不算)。这样就指定我们要跳转到的段了。
然后代码跳转到60行,开始执行保护模式下代码。61到67分别初始化了数据段和栈段,然后就应该加载操作系统代码了(加载代码太长,就不放出来了),最后也是一个段间远跳转跳到操作系统的代码,然后操作系统就转起来了。
分页机制
除了段机制,Intel还提出了极其重要的分页机制。
分页机制提出的缘由
在16位实模式下,由于没有内存模型,计算机只能一次运行一个程序。为了一次性运行多个程序,需要做到两点:
- 保护:某个程序不能被其他程序干扰,这一点随着保护模式的提出已经解决了。
- 重定位:程序加载进内存后需分配给每个程序自己的内存空间,分页机制就是为了解决这个的。
而且分页机制的提出还带来了交换技术和虚拟内存技术,让大于内存的程序可以运行。
分页机制理论
二级分页机制
本来程序是可以直接访问内存中的物理地址的,但是分页机制通过一种手段,将物理地址映射成线性地址。现在的分页机制一般是二级分页:
首先将内存分为称为页框的概念(也称为帧或页帧),一个页框表示一个定长的物理内存,一般页框是4KB,Intel从奔腾CPU开始制定页框是4MB,但是有些系统还是使用的4KB(比如Linux)。
然后是页表的概念,一个页表含有多个页(或者叫做页面),一个页指定一个页框在内存中的位置,页表和页本身也有大小,一般页的大小和页框是一样的。
然后是页目录,用来存储页表的表。
整个映射过程如下:
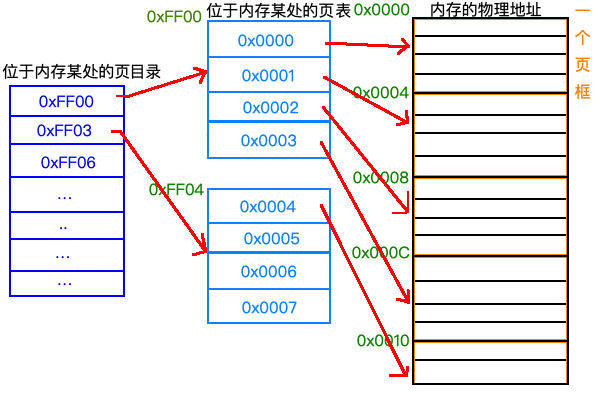
其实二级分页就像字典一样,你要想找到一个地址,你得先查找页目录,通过页目录找到页表,然后通过页表最后找到内存的物理地址。
这里页目录指向页表的物理地址,一个页目录项指向一个页表,这里假设页表在内存中是连在一起的,且页表的大小和页框大小一样是4字节。那么第一个页表的第一个页表项0x0000就是指内存中第一个页框,也就是0x0000~0x0004这四个字节;第二个页表项就的0x0001指向内存中得 第二个页框,也就是0x0004~0x008这一部分字节。
一般来说页表和页框大小都是4KB,这里只是举个栗子。
有了分页机制有什么用呢?显然,我们可以给每个进程一个页目录,这样每个进程都可以使用内存中的任意部分了,但是不能同时使用,这种内存叫做虚拟内存。
那么多进程就好实现了,假设现在有个进程占据着内存在运行,现在CPU执行调度算法,需要将另一个进程换到当前进程所在处,那么我们就可以将当前被占据的页写到磁盘上,然后从磁盘上将需要调度的程序的页载入进来。这样就完成了一次进程切换。
快速分页过程
从线性地址到物理地址转换的速度必须快,否则会很浪费时间。为了加速转换,使用叫做MMU(Memory Manage Unit)的专门硬件来实现转换:
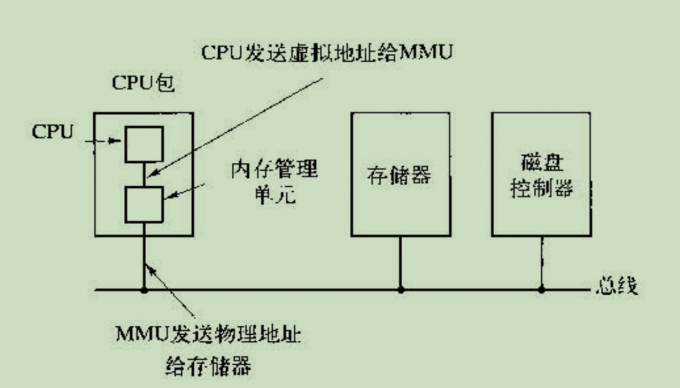
MMU将地址转换后再发给内存和存储器。
MMU里面有一种TBL(Translation Lookaside Buffer)硬件,用于更加快速地转换地址:其内部保存着一个含有少量表项的表:
| 有效位 | 虚拟页面号 | 修改位 | 保护位 | 页框号 |
|---|---|---|---|---|
| 1 | 140 | 1 | RW | 31 |
当一个线性地址到达MMU时,MMU首先将地址和TBL中的所有表项进行同时查找(并行地),如果存在和地址对应的虚拟页面号,则不需要读取页表而直接得到页框号。如果不存在则查找页表,然后将找到的信息随机替换表中的一个行。
别看这么做好像没什么用,实际上这极大地提升了地址转换效率。这个表的原理是根据程序的局部性原理提出的(即上一次访问的代码在短时间内有很大可能也被访问)。
现代的很多CPU没有TBL,都是用软件实现的。如果TBL内没有查找到页面号,则会产生中断,通过操作系统来改变TBL表。
针对大内存的分页
多级分页
之所以使用二级分页(也可能是多级分页)而不是一级分页,主要是为了大内存而设计的。如果使用一级分页的话,在32位系统下,假设页表大小和页框一样是4KB,那么就需要$2^{20}$个页表,占据内存$2^{20}*4=2^{22}=4MB$内存(假设一个页表项的大小是32位的),你想每个程序都得有自己的页表,操作系统自己还有自己的页表,那得占多大内存啊。所以就采用了分页的方法。分页的好处是:不用的页表可以不放在内存中,而且页表不需要一次性映射所有内存,而是只需要映射已经用到的内存即可,这样就节约了页表本身的大小。如果在地址转换的时候发现指向的页表指向的页面不存在,那么会发生一个缺页中断,操作系统会使用页面置换算法处理这个中断,载入新的页(如果不存在指向的页表项的话也会分配页表项)。这样就极大地减少了页表占用的内存。
但是超过三级分页的技术用起来很复杂,所以现在主流CPU都是二级分页
倒排页表
现在来看64位的情况,如果页框还是4KB,那么你得有$2^{52}$个页表,假设每个表项8字节,那你得有超过30000GB的空间来存放页表,就算是使用二级页表也不一定能搞定。所以对于64位系统,提出了倒排页表的骚操作。
具体做法是这样:以往都是页表指定页框所在位置,现在我们反过来:每个页框中包含一个页表项(比如页框的前8个字节),这样我们就不用页表了。也就是说现在是从物理地址找到线性地址。
这个算法极大地节省了空间,但是缺点很明显:最坏的可能需要遍历所有页框。解决办法是通过哈希表来加快查找速度。
32位下的分页机制实例
接下来会展示32位下创建页目录,页表和开启分页机制的代码。再此之前必须看一下Intel对于页目录和页表的格式规定:
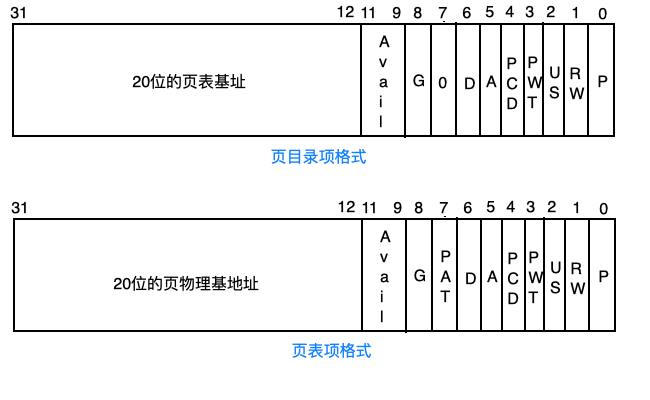
页目录项的格式和页表项的很相似,简单解释一下:
- P位:表示这个页表项指定的页是否存在内存中,为0不存在,不存在会引发缺页中断
- RW位:为0表示这个页只能读取,为1表示可读写
- US位:为1表示所有优先级的程序都可以访问,为0表示只有0,1,2级程序可以访问
- PWT,PCD位:和高速缓存有关,此处不探讨
- A位:访问位,表示这个页是否被访问过,由硬件自动改变值,初始值应当为0
- D位:脏位,表示这个页是否被写过数据,由硬件自动改变值,初始值为0
- PAT位:高速缓存有关,不解释
- G位:页是否是全局的,如果为1表示全局的。全局页会在高速缓存中保存以便更快地被找到。
- Avail字段:没卵用的3个位,程序员可随意使用
- 20位的页表基地址/页物理基地址:指的是页表基地址或物理基地址的前20位。因为页表和物理地址必须是4KB对齐的(因为32位下页表和页框的大小是4KB),所以低12位永远是0,这里只保存其高20位即可。
这里是代码:
| |
略去了GDT表的声明和从实模式跳到保护模式的代码,直接从22行开始看:
25行将页目录的首地址给eax寄存器,PDT(Page Directory Table)是页目录表,PTE(Page Table Entry)是页表入口的意思。这里看第9行的定义知道页目录表放在内存处$0x200000$的位置。而第10行明确了第一个页表的物理地址在$0x201000$处(我们这里所有页表都声明,并且页表和页表间是紧挨着的)
27行将1024传递给ecx,因为页目录需要1024个页表项。
28行清空EDI,29行制作了第一个页目录项,这里$0x007=000000000111$,即P,RW,US三位为1其它位为0。
30到33行的循环放置1024个页目录项,之所以eax要加4096,是因为$4096=2^{12}=1左移12位$,即将高20位(页表物理基地址部分)加1,也就是将下一个页表的物理基地址放入。如果某一个页表暂时不在内存中的话,高20位置0即可(这里我们将所有1024个页表都配置了)。
这个时候页表目录就配置好了,35行开始配置页表,其实是一个道理
35~36行将PTE给eax。
37行说明我们要循环$1024*1024$次,因为一个页目录有1024个页表,而一个页表有1024个页表项。而每个页表项指向的页框则是4KB大小,所以一共就是$4KB*1024*1024=4*2^{10}*2^{10}*2^{10}=2^{32}$,即可达到寻址32位内存地址,整个4GB。
38~43行同理,生成页表项并且放到内存中指定位置。
45~46行通过寄存器cr3指向页目录基地址,这样CPU就能找到页目录了
48~50行通过将cr0的最高位置1,来开启分页机制。至此分页机制开启完毕
52~55行通过跳转清空指令流水线。
那么我们如何使用分页机制呢?使用的方法如下:

当寻址32位的时候,页部件将32位分为3部分,高10位用于找到页表,中间10位用于找到物理地址,最后12位是偏移量。
比如如下指令:
| |
首先根据段地址+偏移地址公式,得到最后的目标地址为0x00801050=0000000010 0000000001 000001010000
页部件首先通过高10位找到位于页目录中的页表。主要是将高10位乘以4(每个目录项4字节)再加上PDT地址,这里为$0x5000+0x0002*4=0x5008$,最终处理器从0x5008处得到了页目录项的值,假设为0x08001000。
然后页部件再从中间10位找到页表项的位置,具体做法也是乘上4然后和0x08001000相加,假设得到最后结果为0x0000C000。
这个0x0000C000就是内存中你要找的页框地址了。最后的12字节就是表示从页框开头的偏移量,所以最后要将0x0000C000加上这个偏移量,为0x0000C050,这就是最后的物理地址。
页面置换算法
最后我们来说一下页面置换算法。页面置换算法是在发送缺页中断的时候,将缺少的页从磁盘上拿取到内存中的算法。
最近未使用页面置换算法(NFU)
页表项里面有一个A位表示此页是否被访问过,和一个D位表示这个页是否被写过。这两个位都是硬件自动修改值的。一般来说硬件会在固定间隔的时间内置这两个位为0。
最近未使用页面置换算法通过A和D位将页面分为4种:
- 第0类:没被访问,没被修改
- 第1类:没被访问,已被修改
- 第2类:已被访问,没被修改
- 第3类:已被访问,已被修改
NRU算法每次都随机地从类编号最小的页面中淘汰一个页面。其优点是容易实现。
最少使用置换算法(LRU)
就是每次都挑选使用次数最少的页面进行置换。这里的难点就在于如何知道页面的使用次数。一般来说可以跟踪A位,看A位被置1的频率来腿短使用的次数。
先进先出置换算法
很容易理解,就是将被调入的页面放在队列末尾,然后每次置换的时候淘汰的队列最前面的页面。这个算法不可靠,因为存在时间最长的页面不一定是使用次数最少的页面
第二次机会置换算法
在先进先出算法上改进的算法。在置换的时候查看队列头部的页面的A位,如果A位为0则表示这个页面又老又没用,直接淘汰。如果A为1则将这个页面的A位清除并放到队列末尾,然后再查看下一个页面。
这个算法的坏处就是总是要移动节点,很耗时间。
时钟页面置换算法
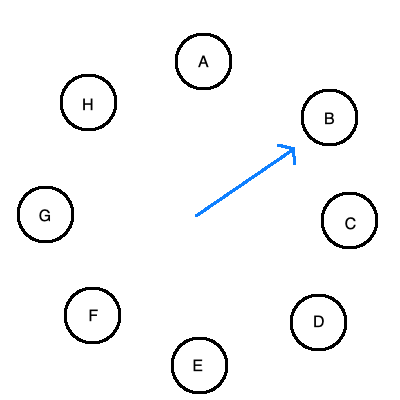
在第二次机会算法上的改进。将进程排成环,有一个表指针指向最老的页面。当发生页中断时,查看指针所在处页面的A位,如果为1则清0然后指向下一位,如果为0则将这个页置换为新的页,并且指针向后移动:
工作集页面置换算法
一般来说,我们采用请求调页的策略,即在一个进程开始的时候,内存中是是没有和这个进程有关的页的,那么进程运行时立刻会产生一个缺页中断,然后运行页面置换算法。在一段时间过后,进程就会在较少缺页的情况下工作。即页面是在需要时被装入,而不是预先装入。
一个进程当前正在使用的页面的集合叫做工作集,不少系统会跟踪进程的工作集,在CPU切换回进程之前确保内存中存在这个进程的所有工作集。通过这种手段来减少频繁缺页而导致的磁盘请求。这种模型叫做工作集模型。下面就来探讨基于工作集的页面置换算法。
为了确定工作集,我们必须确定一个k值作为工作集的最大容量。当前页面和前k-1个页面所组成的页面就是页面集。
基于工作集的置换算法基本上就是找到一个不再工作集中的页面,然后淘汰他。
工作集时钟页面置换算法
很简单,就是将原本的页面换成工作集。