《现代操作系统》的笔记,这里讲述了ELF32文件和ext文件系统。
文件,其实就是磁盘中的一块二进制文本。文件其实有很多种格式,在Unix下使用的是ELF文件格式,而在Windows下则是PE文件格式。这里就来剖析一下ELF文件格式。
ELF32是32位Unix系统下的文件格式,称为Executable Linkable Format,也就是说这一个格式既可以做到表示可执行文件,也可以做到表示链接文件。64位的操作系统使用的是ELF64。
如果你想要看官方的说明文档,直接
即可
首先我们用C语言创建一个可执行的ELF32文件来作为分析样本:
1
2
3
4
5
6
7
8
| #include <stdio.h>
char buffer[8];
int main(){
const char* str = "hello world\n";
printf("%s", str)
}
|
然后在Unix系统下,使用如下命令编译:
1
| gcc -m32 main.c -o main.out
|
-m32指定了编译为32位的,如果你的系统是64位的但是没有加这个选项,会默认编译为64位的。如果你的系统是64位的,那么需要安装32位的辅助库:
1
| apt-get install gcc-multilib
|
接下来验证你的main.out文件是ELF32格式的:
1
2
3
4
| file main.out
#出现如下即可
main.out: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamically linked, interpreter /lib/ld-, for GNU/Linux 3.2.0, BuildID[sha1]=ea6b37ec7e761d92fa742559569d654c9462112d, not stripped
|
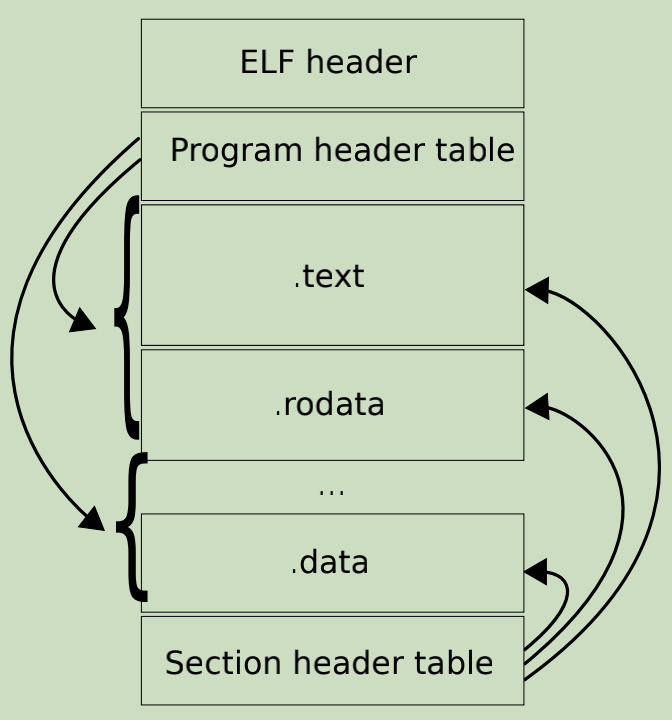
ELF文件中主要有四个部分:
- ELF头(ELF header)。这一部分一定在文件开头,ELF32中占52字节。这个头部指定了程序投标和节头表在文件中的位置,以及一些ELF文件的信息。
- 程序头表(Program header table)。这一部分的位置不固定,一个程序可能有多个程序头表,也可能没有(只有可执行文件才有)。用于指定程序运行时的内存分布。
- 节头表(Section header table)。这一部分位置不固定,一个程序可能有多个节头表。节头表指定了程序中节在程序中的位置(这里的section意义和nasm中section的意义一样,其实就是指定程序段的位置)。
- 程序段。程序的程序段。
接下来一部分一部分看:
通过
可查看头部信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Shared object file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0x3e0
Start of program headers: 52 (bytes into file)
Start of section headers: 6080 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 9
Size of section headers: 40 (bytes)
Number of section headers: 29
Section header string table index: 28
|
顺便将头部信息对应的结构体也给出(Unix系统下的elf.h头文件中就有),我将每个字段在文件中的偏移地址都写在字段上方了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| typedef uint16_t Elf32_Half;
typedef uint32_t Elf32_Word;
typedef int32_t Elf32_Sword;
typedef uint64_t Elf32_Xword;
typedef int64_t Elf32_Sxword;
typedef uint32_t Elf32_Addr;
typedef uint32_t Elf32_Off;
typedef uint16_t Elf32_Section;
typedef Elf32_Half Elf32_Versym;
#define EI_NIDENT (16)
typedef struct
{
//0字节
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
//16字节
Elf32_Half e_type; /* Object file type */
//18字节
Elf32_Half e_machine; /* Architecture */
//20字节
Elf32_Word e_version; /* Object file version */
//24字节
Elf32_Addr e_entry; /* Entry point virtual address */
//28字节
Elf32_Off e_phoff; /* Program header table file offset */
//32字节
Elf32_Off e_shoff; /* Section header table file offset */
//36字节
Elf32_Word e_flags; /* Processor-specific flags */
//40字节
Elf32_Half e_ehsize; /* ELF header size in bytes */
//42字节
Elf32_Half e_phentsize; /* Program header table entry size */
//44字节
Elf32_Half e_phnum; /* Program header table entry count */
//46字节
Elf32_Half e_shentsize; /* Section header table entry size */
//48字节
Elf32_Half e_shnum; /* Section header table entry count */
//50字节
Elf32_Half e_shstrndx; /* Section header string table index */
} Elf32_Ehdr;
|
让我们一个字段一个字段看:
- e_ident[EI_NIDENT]:对应头部信息Magic部分,这是一个魔数,让我们一个字节一个字节看:
- 7F 45 4C 46:ELF开头必须是这四个字节,7F没有意义,
45 4C 46则是ELF三个字母的ASCII码 - 01:对应Class部分的值,表示文件类型
- 01:对应Data部分的值,表示文件编码的方式
- 01:对应Version部分的值,表示ELF头部的版本
- e_type:对应Type部分,表示文件类型
- 0:无效文件
- 1:可重定位文件
- 2:可执行文件
- 3:共享目标文件
- 4:Core文件
- e_machine:对应Machine部分,表示文件的编译平台。为3表示80386
- e_version:对应头部的第二个Version部分,表示这个文件的版本
- e_entry:对应Entry point address部分,表示程序的入口点(如果不是可执行程序则为0x00),这里是main函数所在的位置。
- e_phoff:对应Start of program headers,表示Program header table在文件中的偏移地址,这里是52,表示正好在ELF头的后面。
- e_shoff:对应Start of section headers,表示Section header tbale在文件中的偏移地址。
- e_flags:对应Flags,表示在x86架构下,程序载入时EFLAGS寄存器的初值。
- e_ehsize:对应Size of this header,表示ELF头的大小
- e_phentsize:对应Size of program headers,即Program header table的大小
- e_phnum:对应Number of program headers,即Program header table的个数
- e_shentsize:对应Size of section headers,即Section header table的大小
- e_shnum:对应Number of section headers,即Section header table的个数
- e_shstrndx:对应Section header string table index,即指向保存字符串信息的节的序号(从0开始算)
程序头表中存放着一系列的Segment的信息。
现在来看看程序头表,使用readelf -l main.out即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| Elf file type is DYN (Shared object file)
Entry point 0x3e0
There are 9 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000034 0x00000034 0x00000034 0x00120 0x00120 R 0x4
INTERP 0x000154 0x00000154 0x00000154 0x00013 0x00013 R 0x1
[Requesting program interpreter: /lib/ld-linux.so.2]
LOAD 0x000000 0x00000000 0x00000000 0x00754 0x00754 R E 0x1000
LOAD 0x000ed8 0x00001ed8 0x00001ed8 0x00130 0x0013c RW 0x1000
DYNAMIC 0x000ee0 0x00001ee0 0x00001ee0 0x000f8 0x000f8 RW 0x4
NOTE 0x000168 0x00000168 0x00000168 0x00044 0x00044 R 0x4
GNU_EH_FRAME 0x00061c 0x0000061c 0x0000061c 0x0003c 0x0003c R 0x4
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RW 0x10
GNU_RELRO 0x000ed8 0x00001ed8 0x00001ed8 0x00128 0x00128 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rel.dyn .rel.plt .init .plt .plt.got .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .dynamic .got .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .dynamic .got
|
然后是结构体声明:
1
2
3
4
5
6
7
8
9
10
| typedef struct {
Elf32_Word p_type; //段的类型,或者如何解释此数组元素的信息。
Elf32_Off p_offset; //从文件头到该段第一个字节的偏移
Elf32_Addr p_vaddr; //段的第一个字节将被放到内存中的虚拟地址
Elf32_Addr p_paddr; //仅用于与物理地址相关的系统中。System V忽略所有应用程序的物理地址信息。
Elf32_Word p_filesz; //段在文件映像中所占的字节数。可以为0。
Elf32_Word p_memsz; //段在内存映像中占用的字节数。可以为0。
Elf32_Word p_flags; //与段相关的标志。
Elf32_Word p_align; //段在文件中和内存中如何对齐。
} Elf32_phdr;
|
这里就直接解释readelf输出的信息了:
在Program Headers表中,每一行都是一个Segment的信息。Offset表示这个Segment在文件中的偏移量,FileSiz则表示其大小。而VirtAddr则表示这个Segment应当加载到内存中的哪个位置;PhysAddr也一样,只不过是在未开启分页机制下的物理地址,一般在开启分页机制的系统中值都是相等的。MemSiz则是需要多少内存空间容纳这个Segment。
然后看第一列:PHDR表示本Program header;INTERP则是指定以null结尾的路径名的位置和大小,作为解释器调用,以链接运行时库;LOAD则是必须要加载入内存的Segment;DYNAMIC所指的节包含动态链接的信息;NOTE指定辅助信息的位置和大小;TLS指定线程本地存储模板,从用TLS标志组合所有部分;GNU_STACK是内核使用的字段。
下面的**Section to Segment mapping(节到段映射表)明确地说明了哪些段对应哪些节。第一个LOAD类型的Segment对应02号节,可以看到里面有.text所以是代码段。第二个LOAD类型的Segment对应03号节,里面有.data和.bss有数据段。
节头表则是用来记录节信息的表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 00000154 000154 000013 00 A 0 0 1
[ 2] .note.ABI-tag NOTE 00000168 000168 000020 00 A 0 0 4
[ 3] .note.gnu.build-i NOTE 00000188 000188 000024 00 A 0 0 4
[ 4] .gnu.hash GNU_HASH 000001ac 0001ac 000020 04 A 5 0 4
[ 5] .dynsym DYNSYM 000001cc 0001cc 000080 10 A 6 1 4
[ 6] .dynstr STRTAB 0000024c 00024c 00009d 00 A 0 0 1
[ 7] .gnu.version VERSYM 000002ea 0002ea 000010 02 A 5 0 2
[ 8] .gnu.version_r VERNEED 000002fc 0002fc 000030 00 A 6 1 4
[ 9] .rel.dyn REL 0000032c 00032c 000040 08 A 5 0 4
[10] .rel.plt REL 0000036c 00036c 000010 08 AI 5 22 4
[11] .init PROGBITS 0000037c 00037c 000023 00 AX 0 0 4
[12] .plt PROGBITS 000003a0 0003a0 000030 04 AX 0 0 16
[13] .plt.got PROGBITS 000003d0 0003d0 000010 08 AX 0 0 8
[14] .text PROGBITS 000003e0 0003e0 000202 00 AX 0 0 16
[15] .fini PROGBITS 000005e4 0005e4 000014 00 AX 0 0 4
[16] .rodata PROGBITS 000005f8 0005f8 000021 00 A 0 0 4
[17] .eh_frame_hdr PROGBITS 0000061c 00061c 00003c 00 A 0 0 4
[18] .eh_frame PROGBITS 00000658 000658 0000fc 00 A 0 0 4
[19] .init_array INIT_ARRAY 00001ed8 000ed8 000004 04 WA 0 0 4
[20] .fini_array FINI_ARRAY 00001edc 000edc 000004 04 WA 0 0 4
[21] .dynamic DYNAMIC 00001ee0 000ee0 0000f8 08 WA 6 0 4
[22] .got PROGBITS 00001fd8 000fd8 000028 04 WA 0 0 4
[23] .data PROGBITS 00002000 001000 000008 00 WA 0 0 4
[24] .bss NOBITS 00002008 001008 00000c 00 WA 0 0 4
[25] .comment PROGBITS 00000000 001008 000029 01 MS 0 0 1
[26] .symtab SYMTAB 00000000 001034 000440 10 27 43 4
[27] .strtab STRTAB 00000000 001474 000250 00 0 0 1
[28] .shstrtab STRTAB 00000000 0016c4 0000fc 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
p (processor specific)
|
Nr是序号,Name是节的名称,Type是节的类型,Addr是节应当在内存中的地址,Off是节在文件中的偏移量,Size是节的大小。
对应的结构体如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| typedef struct
{
Elf32_Word sh_name; /* Section name (string tbl index) */
Elf32_Word sh_type; /* Section type */
Elf32_Word sh_flags; /* Section flags */
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Section size in bytes */
Elf32_Word sh_link; /* Link to another section */
Elf32_Word sh_info; /* Additional section information */
Elf32_Word sh_addralign; /* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;
|
其实Section里面还有一个特殊的Section叫做符号表,用于存放所有符号,分别为动态符号表.dynsym和静态符号表symtab。使用-s选项观察。
最后我们再来一个简化版本的分析,直接使用汇编语言:
1
2
3
4
5
6
7
8
9
10
11
12
13
| section .data
str1: db 'hello world'
global _start
section .text
_start:
mov ax, 0
mov bx, 0
mov cx, 0
mov dx, 0
section .bss
stack: resb 20
|
第四行的global是导出_start符号,因为链接器必须要有个对外的代码入口符号才行。将代码保存为main.asm,然后运行:
1
2
| nasm -felf32 main.asm -o main.o #汇编为中间文件
ld -m elf_i386 main.bin -o main.out2 #连接成可执行文件
|
这个文件执行之后会报段错,不过没关系,我们只是拿来研究一下。使用readelf观察Program header table和Section header table:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x000000 0x08048000 0x08048000 0x00090 0x00090 R E 0x1000
LOAD 0x000090 0x08049090 0x08049090 0x0000b 0x00020 RW 0x1000
Section to Segment mapping:
Segment Sections...
00 .text
01 .data .bss
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 08048080 000080 000010 00 AX 0 0 16
[ 2] .data PROGBITS 08049090 000090 00000b 00 WA 0 0 4
[ 3] .bss NOBITS 0804909c 00009b 000014 00 WA 0 0 4
[ 4] .symtab SYMTAB 00000000 00009c 0000b0 10 5 7 4
[ 5] .strtab STRTAB 00000000 00014c 00002d 00 0 0 1
[ 6] .shstrtab STRTAB 00000000 000179 00002c 00 0 0 1
|
显然,由于我们在程序里面定义了.text,.data,.bss段,而且这些段都是程序运行时的必须段,所以存在两个LOAD类型的Segment指示我们要将这三个段载入内存中。而除了这几个段之外,nasm还自动定义了.symtab(符号表)——因为我们使用了符号_start,stack,str1;.strtab(字符串表)——因为我们使用了字符串常量hello world;和shstrtab(段表字符串表)——因为我们声明了段。
然后使用-s参数详细查看.symtab的内容:
1
2
3
4
5
6
7
8
9
10
11
12
| Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 08048080 0 SECTION LOCAL DEFAULT 1
2: 08049090 0 SECTION LOCAL DEFAULT 2
3: 0804909c 0 SECTION LOCAL DEFAULT 3
4: 00000000 0 FILE LOCAL DEFAULT ABS main.asm
5: 08049090 0 NOTYPE LOCAL DEFAULT 2 str1
6: 0804909c 0 NOTYPE LOCAL DEFAULT 3 stack
7: 08048080 0 NOTYPE GLOBAL DEFAULT 1 _start
8: 0804909b 0 NOTYPE GLOBAL DEFAULT 3 __bss_start
9: 0804909b 0 NOTYPE GLOBAL DEFAULT 2 _edata
10: 080490b0 0 NOTYPE GLOBAL DEFAULT 3 _end
|
显然我们定义的符号都保存在符号表中,除此之外nasm还为我们增加了一些额外的符号。
说完文件之后我们来说明一下文件系统。
磁盘,软盘,CD和U盘一般以块分割,每一个块是512字节(关于IO详见第六个笔记)。第一个块被称为主引导扇区(Master Boot Recorder),机器在启动的时候会自动地读取主引导扇区的512字节,放到0x7C00:0x0000的内存地址处,并且跳转到0x7C00:0x0000的地方执行代码。一般来说,MBR存放着加载器的代码。
如果你安装过Ubuntu,那么当你从U盘启动的时候,会看到Ubuntu的安装程序。这是因为加载器将Ubuntu安装程序加载到内存中后,将控制权交给了安装程序。安装程序将本来存在在U盘上的操作系统安装到电脑硬盘上,并且留下引导代码,以便于你开机进入系统。
一般来说,在MBR的最后存在一个分区表,用于指定磁盘的分区情况。分区是指将磁盘单独划分出来的一个区域,一般一个分区中会暗转搞一个文件系统,即一个分区对应一个文件系统。这样说来,你可能会想到在安装多系统时必须先对磁盘分区和格式化,这也正是为了操作系统的运行。
一个文件系统一般在开头是一个引导块,用于装载该分区的文件系统;紧接着是一个超级块,包含文件系统的所有重要参数;然后就是文件的内容等信息。
文件存储的实现的关键是确定哪个文件在哪些磁盘块上,这里有几种方法:
将每个文件作为连续的数据存放在磁盘上,所以如果一个文件尾40KB,那么在块大小为1KB的磁盘中就得占用连续的40个块:
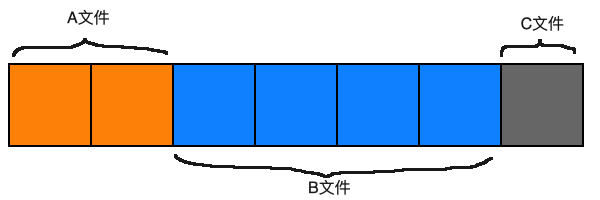
但是这种解决方法显然有缺点:随着时间的推移,可能些块因为太小而一直没有存储文件(产生空洞),导致磁盘变得零碎。而且一般来说不系统不会自动整合空洞,因为这样要遍历整个磁盘,很耗时间(而且这个时间是和磁盘大小成正比的,这意味着操作系统没办法通过算法控制时间)。
在Windows7中,通过附件->系统工具菜单就可以找到磁盘碎片整理程序,这个程序就是为了处理空洞的。运行一次所需的时间还是比较长的。
或者可以通过维护一个空洞列表,记录下空洞位置和大小,在创建文件的时候寻找可以容纳的空洞。但是这个方法也很有问题:必须在文件创建前得知文件的大小。试想你在打开Vim新建文件编写代码的时候,Vim却要你确定文件大小才让你进行编辑。这是一件很让人烦的事情。
办法就是将文件放在不同块中,并且以链表的方式记录:
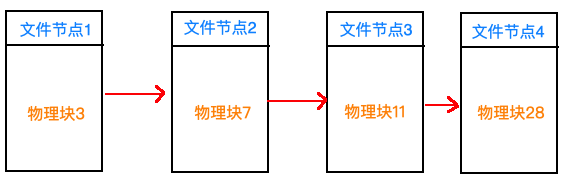
这样就可以很好地利用磁盘了。但是由于不是随机存储,查找文件会很耗时(尤其是磁盘这种很“笨重”的硬件),而且一般来说我们在每个物理块的前几个字节防止指向下一个物理块的指针,可能会导致物理块中剩余空间的大小不是2的幂,这也会影响CPU读取文件的速度。
看了链表分配后,你想不用在每个块前放置指针,而是将指针全部放在一张表里面不就行了。内存中的链表分配方法正是这么做的:
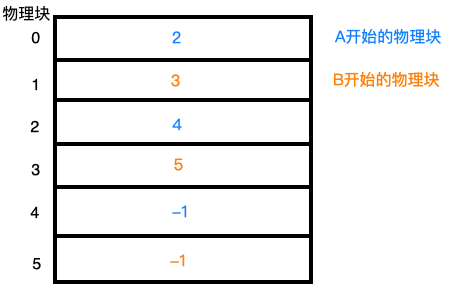
A的块为0,2,4,B的块为1,3,5。这种表称为FAT(文件分配表)。
这种方法也有明显的缺点:在文件和磁盘不断增大的情况下,内存中的这个表会越来越大,内存可能无法承受。
最后要介绍Unix系统一直在用的inode方法,下面是inode的结构示意图:
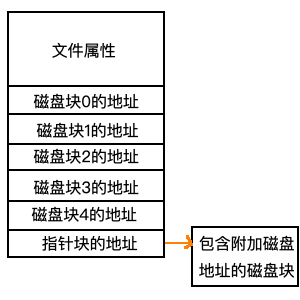
inode保存着文件的属性,像是文件名称,文件GID,UID,权限,大小等等属性(需要注意的是这些属性并不是在ELF文件中定义的)。然后使用指针指向文件各部分所在磁盘块的地址。如果inode有大小的话,超出的磁盘块会存放在附加磁盘地址中,并且使用指针标明。
一般来说可以将所有的目录列成表存储在磁盘中:

如果使用了inode,还可以将文件属性放在inode中而不是目录项中。
Windows使用第一种方法,Unix使用第二种方法。
现在试想这样一个情况:你的WPS在写入文件,这个时候电池突然没电了,电脑关机。那么在关机之后磁盘的情况是怎样的呢?如果不采取一些措施的话,磁盘中将会存在WPS文档的部分信息,并且在开机之后不会将剩余部分的信息写入。这个时候磁盘中就会多出一块没用的空间,造成空间浪费。
日志文件系统就是为了避免这种情况而诞生的。其基本思想是:每次读写磁盘的动作都作为日志记录在磁盘中。如果出现断电重启情况,系统会先查看日志,继续执行未完成的操作。
LFS一般还有一个清理线程,用于定时清理没用的日志。
而且LFS还有利于更好地提升磁盘读写效率:LFS可以在将文件读写的操作延后,等到存在连续扇区或柱面读取的时候再一次性读取,这样会快很多。
即使在同一个计算机的同一个操作系统下,也有可能有不同的文件系统。你可以在你的Linux系统上使用df -T来查看各个文件系统:
1
2
3
4
5
6
7
8
| Filesystem Type 1K-blocks Used Available Use% Mounted on
udev devtmpfs 998020 0 998020 0% /dev
tmpfs tmpfs 204096 2772 201324 2% /run
/dev/vda1 ext4 41152812 3984212 35264944 11% /
tmpfs tmpfs 1020464 0 1020464 0% /dev/shm
tmpfs tmpfs 5120 0 5120 0% /run/lock
tmpfs tmpfs 1020464 0 1020464 0% /sys/fs/cgroup
tmpfs tmpfs 204092 0 204092 0% /run/user/1001
|
可以看到,在/dev目录下下挂载的是devtmpfd系统,而在/目录下则是ext4文件系统。
Windows的做法是将磁盘分区,然后每个区一个文件系统,比如C盘,D盘等都可以是不同的文件系统。但是同一个盘下必须是一个文件系统。
Linux就不一样了,它尝试将所有的文件系统整合一个统一的结构中,所以就提出了VFS。
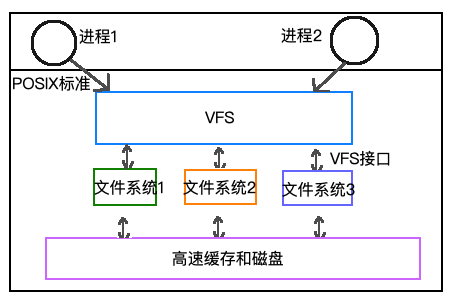
VFS的核心思想就是通过VFS层将不同的操作系统掩盖起来,并且提供统一的POSIX标准的访问方式给进程。
ext系列文件系统一直是Unix使用的文件系统,从ext1到最新的ext4。这里我们拿比较经典的ext2来说明。首先来看一下ext2的格式:
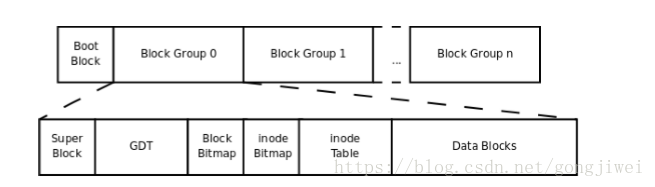
首先存在一个启动块(Boot Block),用于用以安装启动管理程序。然后是各个不同的ext2文件系统。
每个文件系统的开头为一个超级快(Super Block),用于记录本分区的信息(inode/block总量,大小,剩余量等)。然后是一个块组描述符表(Group Description Table),整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
然后是块位图(Block Bitmap),用1和0表示其后的块是否被占用(下面会说),然后是inode位图(inode Bitmap),用1和0表示inode项是否有用。
然后是inode表(inode Table),里面存储了一系列的inode。
最后是数据块,存储着用户数据。
块位图的思想是这样的:由于磁盘分为很多个块,所以可以用一个长列表来表示每个块是否被占用,为0表示没有被占用,为1表示被占用。由于经常从形式上将长列表折叠成表格,所以叫做块位图:
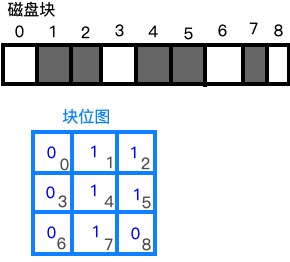
这里磁盘块的标号表示第几个磁盘块,灰色表示已经被占用。
下方的块位图中中间数字表示是否被占用,角标表示对应的磁盘块序号。
inode位图也是一样的思想。
CSDN博客1
CSDN博客2