《计算机网络:自顶向下方法》的学习笔记
应用层是我们应用程序所在的层,程序员编程的时候只需要了解应用层的相关知识。应用层将复杂的硬件和协议,和应用程序隔离开。
由于应用层主要是一些应用。所以我们这里主要看一些典型的应用层应用。
客户-服务器模型(CS模型)
首先要说的是客户服务器模型。在网络通信中,等待连接的一方叫做服务器端,而主动连接的一方叫做客户端。客户端连接到服务器之后可以使用要求服务器提供一些服务。举个栗子:你去餐馆吃饭,那么餐馆的服务员就是服务器端,因为他们要一直在餐馆等着客人来就餐,然后提供相应的服务。他们不能随意离开餐馆。但是客人就是客户端,客人想来就来,想走就走,并且可以要求一些服务。而且客人是主动方,客人可以选择是否踏入餐馆,而服务员则不能硬拉着客人就餐。同样的,客户端需要服务的时候需要主动连接到服务器,服务器则不能主动连接客户端。
CS模型是网络上最基本的应用程序模型。再举个栗子:你打王者荣耀的时候,是不是想什么时候上分就什么时候上分(也可能是掉分),所以你的王者荣耀软件就是客户端,每次当你想上分的时候就需要连接到王者荣耀服务器。而服务器是由腾讯自己维护的,一天24小时不间断开着,所以你只要一打开王者荣耀,你的客户端就可以自动连接上服务器。然后服务器会传给你一些信息,包括匹配队友的信息,以及峡谷中各个队友的位置啊,伤害啊,技能动画等。
还有一种对“服务器”的解释,是硬件方面的,指一台运行着服务器程序的电脑或机器。因为服务器程序基本上要二十四小时开着,还要处理大量的流量,写日志什么的,所以一般不会将自己的PC当服务器,而是买一台服务器(硬件上的)。买来的服务器基本上性能比PC好得多,可以处理网络上的各种信息通讯。
不过现在这个时代不需要真的买个几吨重的服务器回来,现在各大厂有“云服务器”,也就是说服务器机子在他们那边,但是你可以通过网络连接到你买的服务器,然后操控服务器机子。阿里云和腾讯云就是出售云服务器的平台。
其实服务器机子本身也没什么特殊的,你可以把它当做性能很好的电脑,所以也得安装操作系统,而且服务器程序你也得自己写,服务器本身是没有的。
编写网络程序
这一部分是一大块独立内容,这类就不提及了,如果你想要编写自己的网络程序的话,网站方面可以上百度搜索“HTML CSS JS”,而服务器和客户端程序的话,Windows推荐《WinSocket编程》,Unix推荐《Unix网络编程:卷一》,Perl语言推荐《Perl网络编程》。基本上大部分语言都带有网络编程的API,C/C++需要依赖操作系统自身API,而Python,Java这种跨平台的本身就带有网络编程API,你可以直接搜索相关教程学习。
IP地址和端口号
当客户端连接到服务器端的时候,客户端怎么知道服务器端在哪里呢?简单来说,路由器在发送客户端的信息时,怎么知道服务器端在哪里呢?
首先路由器会按照IP地址找到服务器程序所在的电脑(每个电脑只有唯一的IP地址,由硬件厂商生产网卡时写入网卡内的,不可改变),然后再在目标电脑上通过端口号找到目标程序,然后和程序通讯。也就是说,在同一个主机上,端口号用来区别不同的程序。
无论是客户端程序还是服务器程序,都需要绑定一个端口号,一个端口号只能由一个程序使用。
端口号的取值范围为0~65535,前255个端口号是常用端口号,用于一些广为人知的应用程序(下面会说),一般不用做自己的程序(除非你实现的就是那些“广为人知”的程序)。
基于TCP的程序和基于UDP的程序
在应用程序下的层——传输层中,存在两个很重要的协议:TCP和UDP。我们大多应用程序都是基于这两个协议的。
TCP协议的特点
- 可靠的数据传输:TCP协议采用一系列方式让传输变得可靠,包括超时重传(如果超过一定时间服务器还没有相应,那么再将之前的信息传一遍),使用报文传输等
- 面向连接的服务:在通信前TCP需要通信双方建立全双工连接,这样传输的数据在连接中进行,比较不容易被窃听。
UDP协议的特点
- 无连接的服务
- 不可靠的传输
这个时候就有人问了:你这个UDP干啥啥不行,为什么不直接用TCP呢?因为UDP传输很快,而且不会超时重传,传输失败的数据直接丢弃。这一点广泛用在音视频通话,在线会议上。因为这些程序对同步性有很高的要求。如果你用TCP,有一帧的数据没传到,那TCP还得重传,那到时候你的延时就比别人大了。而UDP不管传没传到,反正我就接着传。这样虽然中间几帧丢失了,你顶多也是看到画面突然切了一下,不会有延时。
所以在编写程序的时候,你需要指定程序是使用TCP还是使用UDP。使用TCP的程序就是基于TCP的,使用UDP的就是基于UDP的。
一些广为人知的应用程序(常用应用程序)
网络上有很多常用的应用程序,系统为他们保留了相关端口号。下面让我们来看看:
HTTP服务
即超文本传输协议,主要体现就是传输Web页面,也就是你浏览器天天打交道的对象(浏览器可以看成HTTP客户端)。系统保留端口号80,基于TCP。
特点
主要特点是无状态协议,也就是说不会记录通信对象的信息。他把网页传给你之后就忘了这件事情。你要想再让他传给你,你得再次建立TCP连接,要求他再传一份给你(浏览器上就是按刷新按钮)。
而且你在网页中填写的信息(比如登录名称啊,密码啊)他也不记得,你要想重新登录得自己输入。
这个时候有人就问了:不对啊,我登录网页的时候它会帮我自动登录啊,或者问我用不用以前保留的密码之类的。这个不是HTTP的事情,是cookie的事情。
非持续连接和持续连接
HTTP可以选择是非持续连接还是持续连接。非持续连接就是他把信息传给你之后,TCP连接就关闭了。持续连接就是他传给你之后还等着,不断开连接(这些在下文请求报文中有体现)。
浏览器对象
网页中除了有文字,还有图像什么的对吧。文字本身(也就是HTML文件)是一个对象,图像是对象,CSS和JS文件也是对象。在非持续连接中,每个对象是需要单独建立TCP连接传输的。也就是说,浏览器先建立一个连接,传给你HTML文件了,然后关闭连接,再打开一个新连接,传给你一个图片,再关闭这个连接。。。如此往复,直到所有对象传输完毕。
这显然很麻烦,所以一般使用持续连接:所用东西用一个连接顺序传输,传完再关闭连接(或者继续等待)。
HTTP报文格式
HTTP报文分为两种:请求报文——用于客户端发给服务器,请求一些数据;响应报文——服务器根据传过来的请求报文,发送回去的含有数据的报文。
这里顺便说一下:报文的换行符不是\n,而是\r\n。也就是说每一行的末尾其实是\r\n。
请求报文
典型的请求报文如下:
GET /dir/index.html HTTP/1.1
Host: www.webpage.com
Connection: close
User-agent: Mosilla/5.0
Accept-language: zh
第一行为请求行,后面的叫做首部行。
请求行有三个部分:请求方法,请求的资源,使用的HTTP协议。这里请求方法是GET,表示我要接收数据,还可以是:
POST:表示我要发送数据了,一般你在登录的时候,填完用户名和密码,点登录时就会发送POST请求HEAD:和GET一样,只不过要求响应报文中不要有内容,只返回响应报文头部即可。DELETE:指定删除一些页面
等。其他的请自行上网百度。
请求的资源很好理解,就是你想要什么。比如你想要服务器上,位于picture文件夹下的a.jpg,那么可能就是/picture/a.jpg。这里要获得dir文件夹下的index.html文件。
HTTP协议部分也很简单,这里指定使用HTTP1.1版本协议。
首部行第一行为Host信息,表示请求的主机名称。第二行Connection表示使用持续连接还是非持续连接。这里的close表示发送完就关闭,显然是非持续连接。第三行指定客户端的信息,这里是火狐浏览器的代号,表示是火狐在请求。最后一行是要接受的语言。如果服务器提供相关语言的网页的话,会返回给你,否则返回默认语言的网页。这里请求的中文网页。
由于是GET方法,所以只有请求行,没有请求内容。但是如果是POST方法,则需要将额外信息附加到请求内容中,类似这样:
请求头\r\n
\r\n
信息1\r\n
信息2\r\n
请求头和信息之间有一个空行。
响应报文
一般格式如下:
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2020 02:02:03 GMT
Server: Apache
Content-Type: text/html
datas
第一行为状态行,下面的四行为首部行,然后是实体行(存储数据的部分)。
状态行说明了:HTTP信息,状态码和状态码描述。这里200表示成功,描述为OK。我们常见的404就是指内容找不到。
第三行的Date字段表示了传输的时间
第四行的Server表示使用的服务器软件类型,这里是Apache服务器软件
第五航Content-Type表示实体行的数据类型。这里是html文本。
更多关于报文的说明请自行百度。
Cookie
为了达到自动登录类似的效果,浏览器需要保存用户信息。这就要用到Cookie。
具体的过程是这样的:假设你现在登录到github,传了你的用户名和密码。当github的服务器确认用户名和密码正确之后,会在它的数据库里面保存你的信息,并且生成一个标识你信息的ID,然后将这个ID放在响应报文的set-cookie字段中传给浏览器。
浏览器收到了登录成功的网页和set-cookie字符,就知道你的信息可能需要记录下来了,就会弹出个对话框问你要不要保存你的信息。如果你点是,那么浏览器就会把你的信息保存下来,这个信息就叫做cookie。
过了几天之后,你再次打开github登录界面,浏览器会先检查有没有保存cookie,有的话他不用你多说,直接自己发送一个POST请求给github服务器自动登录,或者帮你在用户名和密码栏里面填好。这就实现了密码记忆和自动登录了。
所以说了这么多,你可能发现了:HTTP并不知道cookie的保存和传输,最多也只知道set-cookie字段器而已。HTTP不知道cookie的具体内容,cookie的保存和发送都是浏览器和服务器干的事情。所以拥有cookie和HTTP是无状态连接的事实并不冲突。
Web缓存和代理服务器
作为Web缓存的服务器叫做代理服务器(或者Web缓存器)。就是新搞一台服务器,这个服务器叫代理服务器。每次浏览器发送请求的时候先发送到代理服务器,代理服务器如果没有信息,就会再将请求发送给真正的服务器。那么真正的服务器会返回一个响应,也是先到代理服务器(因为是代理服务器给真服务器法的请求),代理服务器会将这个响应保存一份,然后发个客户端。下次客户端再发送同样的请求后,代理服务器会先检查自己有没有请求的信息,有的话直接返回,就不用劳烦真路由器了。
需要Web缓存的意义很明显:降低真服务器的负担,使得响应时间更短。
而且这里要注意一点:代理服务器由于不知道真服务器的内容是否更新了,会不定期请求真服务器发信息给自己,来更新自己的数据。所以代理的内容并不是会永远存储的。
有时候你明明将文件上传了,但是刷新之后页面却没有显示新文件,等了一会再刷新又有了。那么这个时候就是代理服务器给你的反馈,在你等待的时候代理服务器更新了自己的内容。
有时代理服务器不仅仅用作Web缓存,还可以干其他的事情:
正向代理和反向代理
正向代理
正向代理的意思是说,如果你想要访问一个服务器A,但是不能直接访问到,那么你可以通过配置一个代理服务器B,然后让代理服务器B去访问服务器A。这样你就可以通过服务器B来访问服务器A了。
正向代理的典型应用就是翻墙。假设你想要访问谷歌,但是大陆没办法直接访问,但是假设台湾可以,而你又可以直接访问台湾的服务器,那你就可以在台湾设置一个代理服务器,每次要访问谷歌的时候就先请求代理服务器,让代理服务器访问谷歌,然后将信息传给你,就相当于你自己访问了谷歌。
反向代理
和正向代理一样,都是通过代理服务器间接访问目标服务器。和正向代理不同之处在于,用户并不知道自己访问的服务器是代理服务器。也就是说,你以为你访问的是谷歌,其实你访问的是台湾的代理服务器。
反向代理的例子就是防止黑客破坏。比如黑客黑入了你的代理服务器(他以为是真服务器),在里面传播病毒,你的代理服务器挂了,但是你真正的服务器没事,这样就不影响你的网络程序和数据。也就是说黑客只是黑了一个替身而已。
两者的区别就是正向代理需要用户手动配置,并且用户知道访问的是代理服务器。而反向代理由目标服务器方配置,用户并不知道访问的是代理服务器。
负载均衡
当客户请求量特别大的时候,单一服务器可能吃不消,这个时候就可以通过代理服务器(一般是反向代理)将请求分发给多个服务器(称为集群),让多个服务器处理:
| |
这样就可以加快处理速度了。
有人说那请求多了代理服务器炸了咋办?那当然可以增加多个代理服务器咯~~(有钱真好)~~。
动静分离
一般也是使用反向代理。所谓动静分离,就是将动态请求和静态请求分离给不同的服务器处理:
| |
这样就可以加快处理速度了。这样的好处是,如果静态请求处理完了,我们就可以先展示Web页面,不让客户干等着,在客户看页面的时候处理动态请求,这样客户关闭页面的概率会变小。
和HTTP服务器交流
现在让我们真正地和HTTP服务器交流一下(而不是通过浏览器)。我们使用telent程序和百度的HTTP服务器交流。
首先在终端输入以下命令:
| |
第一个参数是百度网址,第二个参数是你要请求的端口(所以telnet还可以请求其他端口,我们在后面会用到)。
然后回车,看见这个就是成功了:
| |
然后我们想要得到百度的首页,那我们得写一个请求报文对吧。我们就照着上面的例子改一个简短的:
| |
然后敲两下回车,你就能看到百度首页的html文件内容了。
网络邮件服务
网络邮件有很多的服务,下面分开看
SMTP
SMTP是网络邮件传输和查询和核心协议。其要求每个报文采用7位的ASCII编码。如果有图像等也需要将其编码为7bits ASCII码。端口号25。基于TCP。
这个协议很复杂,这里就不细说了,如果想要使用telnet连接的话可以看这篇文章。总之来说就是可以收发邮件
POP3
POP3是一个只能查阅邮件的协议,和SMTP不一样,他不能发。端口号为110。基于TCP。
这个协议非常简单,我们这里连到QQ邮箱试一下。
先用telnet连接到QQ邮箱的POP3服务器(使用前得先打开QQ邮箱的pop3通讯功能):
| |
看到下面信息即成功:
| |
然后你得登录,输入:
user 你的用户名(QQ号即可,不需要加@qq.com)
回车,如果成功会显示+OK。然后输入密码(这里的密码是QQ邮箱给你的加密密码)
| |
回车,成功显示+OK。然后你就可以使用list列出所有邮件,retr得到邮件内容,dele删除邮件,quit退出登录了。
DNS服务
用于通过主机名查找IP地址的服务,端口号53,基于UDP。
在浏览器上网的时候,你输入 www.baidu.com 就能请求到百度服务器。但是你要知道,程序是通过IP地址和端口号找到的服务器。那么 www.baidu.com 这个字符串是怎么转化到IP地址和端口号的呢?这就是DNS的功能了。
像 www.baidu.com 这种比较好记的名字叫做主机名,或者叫做域名,是方便人记忆的,但是不包含任何主机信息。DNS可以通过域名来找到对应的IP地址。那么你的浏览器又是怎么知道端口号的呢?因为HTTP服务器的默认端口号为80,所以浏览器默认访问80端口。
找到百度IP的过程类似如下:首先你的浏览器发送 www.baidu.com 给DNS客户端,然后你的DNS客户端会找一个DNS服务器请求这个域名的IP,这个DNS服务器被称为本地DNS服务器。
然后本地DNS服务器会将顶级域名.com发送给根DNS服务器,由他来解析.com域名,然后返回给你一个IP地址。
然后本地DNS服务器根据这个IP地址会找到TLD DNS服务器,这个服务器会解析baidu.com域名,然后返回给你一个IP地址。
然后本地DNS服务器会根据这个地址找到权威DNS服务器,权威DNS服务器会解析www.baidu.com域名,返回IP地址。
这个时候,本地DNS服务器就知道百度的IP地址了,将IP传回给原本的客户端,完成转换。
从上面的情况我们可以发现,DNS服务器同时也是客户端,他也会发送请求给其他的DNS服务器。
上面的情况可绘制成下图:
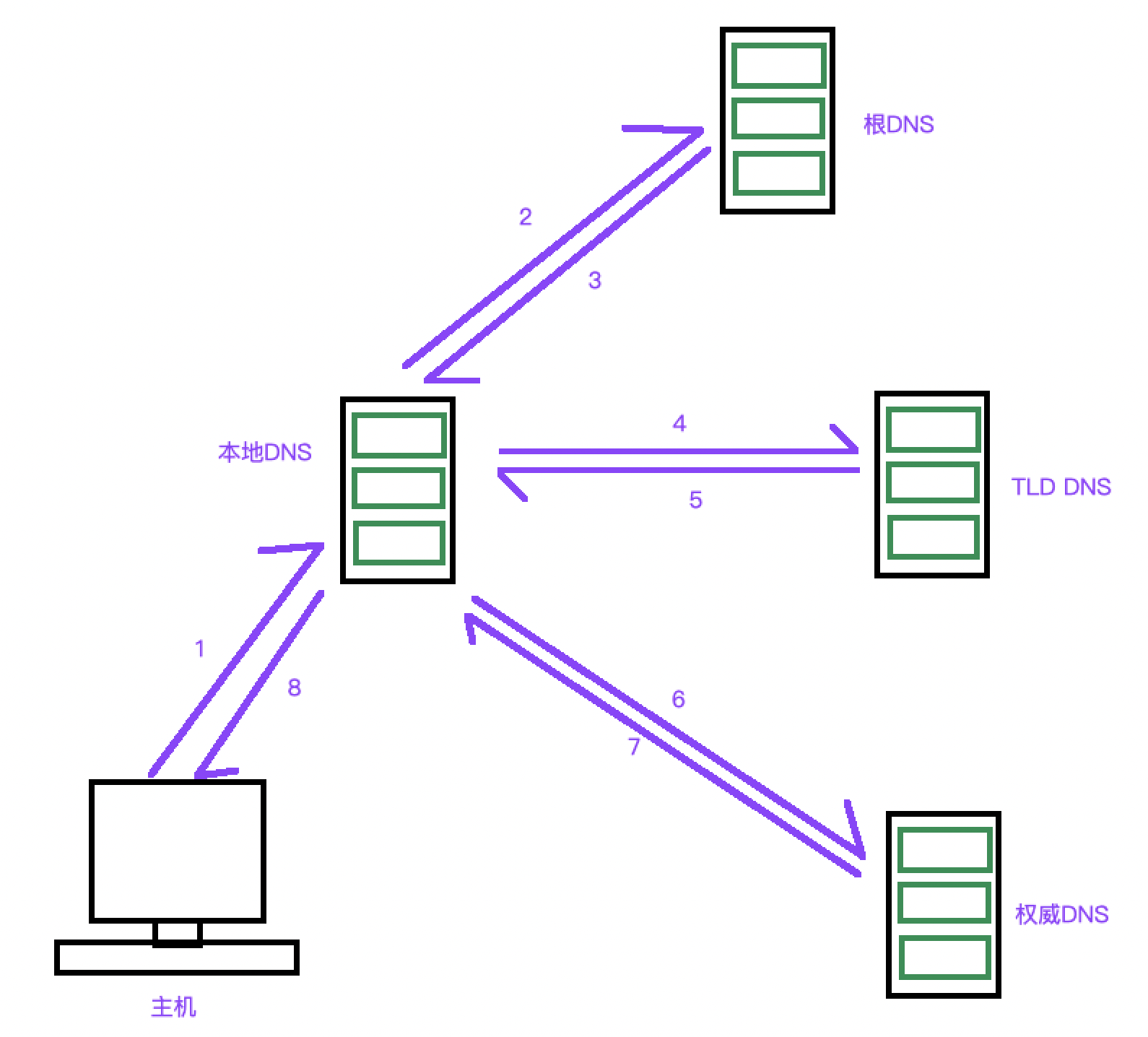
但是有时会是这种情况:
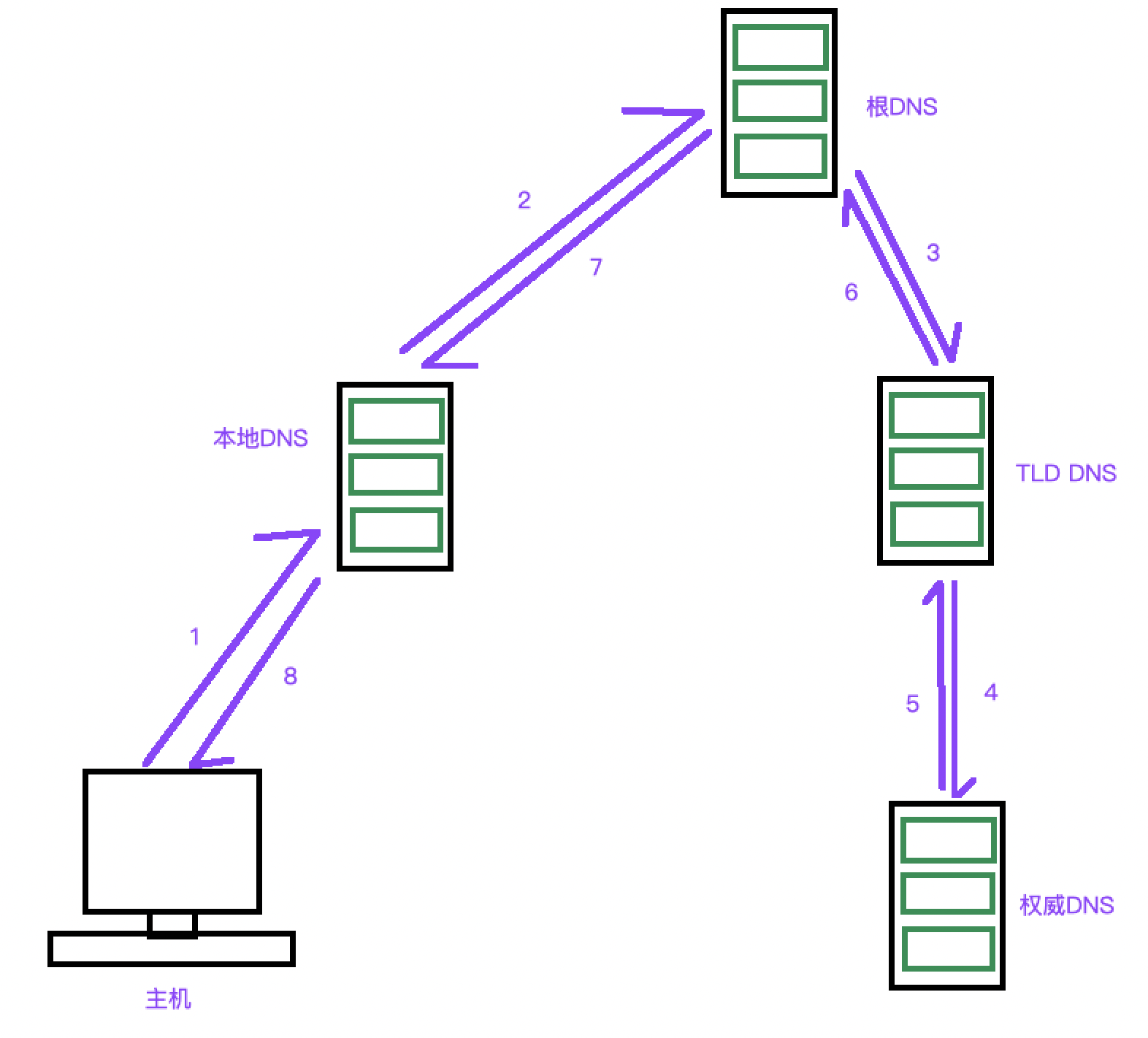
对比一下就知道这种情况是什么情况了。
所以DNS服务器不仅仅只有一台,而是有许多台。可能ISP中就有一台,或者其他的有几台。而且DNS是程网状的,根节点处是根DNS。
使用DNS服务
直接用telnet不行。这里得使用专用工具nslookup。你只要吧网址传给他他就可以返回IP地址和别名。你也可以通过参数来显示器查找的路径。