在使用C++ atomic原子变量的时候,需要指定内存序(memory order),比如memory_order_relaxed,memory_order_acquire等。我一直没搞明白这些内存序是在做什么。这几天深入理解了一下于是写下这份文章。
Cache相关
Cache类型
这一部分是扫盲,也算是备忘。Cache分为三级。L3 Cache, L2 Cache, L1 Cache:
- L3 Cache:向下直接和内存交互,向上和L2 Cache交互,一般只有一条L3,对所有L2 Cache可见
- L2 Cache:向下直接和L3 Cache交互,向上和L1 Cache交互。可能所有核心共享一份L2 Cache,也可能不是,得看CPU架构
- L1 Cache:向下和L2 Cache交互,向上和CPU核心交互。每个核心都有自己的L1 Cache,不互相共享。L1 Cache又分为存储数据的L1d Cache和存储指令的L1I Cache
从L3到L1 Cache,容量越来越小,速度越来越快,造价越来越贵。此外CPU内还有寄存器,速度最快。
Cache映射算法
每次访问数据时,需要检查数据是否在Cache中。如果不在需要从主存-> L3 -> L2 -> L1这样一步一步将数据放到Cache里面,这样CPU才能看到值(刷新Cache Line)。如果数据在Cache中称为缓存命中。给定一个内存地址,通过映射算法找到在Cache中对应的数据(如果不存在就从主存内取)。
Cache的最小单位不是字节,而是Cache line,一般为64字节。
有三种映射算法:
直接映射(Direct Mapped)(已淘汰):将地址拆分成三部分—— |Tag标记|Index|Offset|
Index:当前地址应该存储在哪个Cache line中
Offset:当前地址指定的值在这个Cache line中的偏移量
Tag标记:当前地址是否对应这个Cache Line
假设地址A是64位的,现在有8个Cache Line,每个Cache Line 64字节,这样Offset是6位(2^6 = 64)。Index是3位(2^3 = 8),剩下的55位就是Tag标记。
首先,计算这个地址应该对应哪个Cache Line,通过 (A >> 6) & 0b111得到当前应该在哪个Cache Line。
然后,看对应的Tag (A >> 9)和当前Cache Line记录的Tag(没错Cache Line除了记录64位数据还得记录Tag,甚至可能有一些元数据),如果两个Tag相等,说明此时地址对应的数据已经在此Cache Line中,那么不刷新此Cache Line(注意Cache Line也可能失效,因为主存内的数据比Cache Line中的新,这个时候元数据里会记录这个状态,会刷新Cache Line),否则进行Cache Line刷新。那么接下来要从此Cache Line中取得数据,通过 A & 0b111111 得到地址在Cache line中的偏移量,返回给CPU。
这个缺点很明显:如果两个常用块映射到同一个Cache Line,则这个Cache Line会不停地刷新(被反复替换),就算有空的Cache Line也用不上。
全相连映射(Fully Associate)(已淘汰):将地址拆成两份——|Tag标记|Offset|
查找时将所有Cache Line的Tag与要求的地址Tag并行比较(通过硬件实现)。优点是速度更快,缺点则是硬件昂贵。
组相连映射(Set Associate):把Cache Line分为若干组,每组N行(称为N路组相连)。地址拆成三份——|Tag标记|Set Index|Offset|
假设分为4组,每组8个Cache Line,每个Cache Line也是64字节。那么Set Index是2位,Offset则是6位,剩下56位是Tag标记。
对于64位地址A,首先确定其在哪个组,(A >> 6) & 0b11,然后对组内所有Cache Line判断哪个Cache Line的Tag相等(硬件并行),找到对应的Cache line,然后通过Offset在这个Cache Line中找到对应位置。
如果缓存未命中,则执行粗略的LRU算法,将长时间不用的Cache Line替换。这样就比直接映射更好,减少了同一个Cache Line被重复替换的情况。比起全相连映射,硬件比较器的成本也更低。
MESI
刚才说了Cache映射算法。有一种情况未讨论,就是当目标地址和Cache Line都对的上,但是对应主存内的数据比Cache Line要新,此时Cache Line也要更新。那Cache怎么知道主存内数据更新呢?这就是MESI(CPU缓存一致性协议)的用途。
MESI由四种状态组成:
- M(Modified):此Cache Line的数据被CPU更改过,与主存值不同,如果其他Cache Line要读主存这块数据,此Cache Line必须先写回主存
- E(Exclusive):此Cache Line数据与内存一致,且只有此Cache Line有这份数据(独占)
- S(Shared):此Cache Line数据与内存一致,但有多个Cache Line持有这份地址上的数据(共享)
- I(Invalid):该Cache Line无效(可能是开机启动时还没写入值,或者被别人写入失效)
MESI本质上是个状态机。具体如下(直接抄的Wiki,Wiki上说的很清楚,但是图好像画错了,我改了一下):
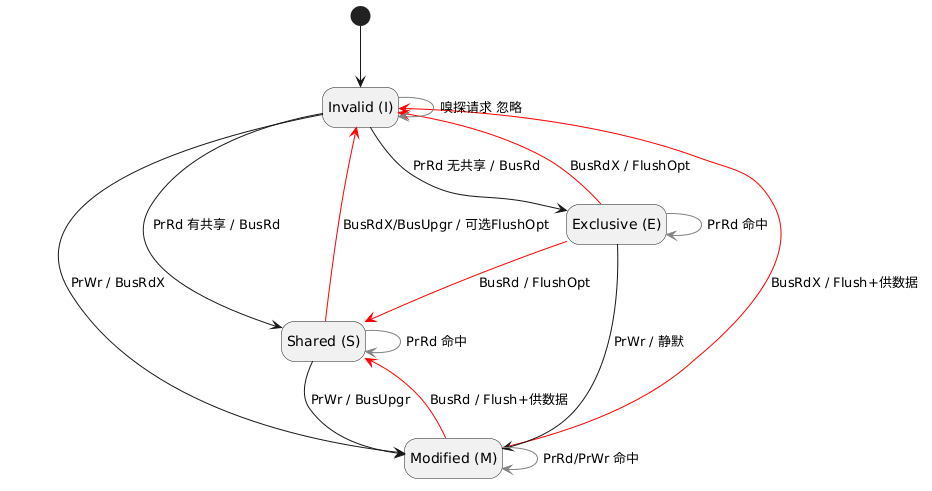
处理器对Cache Line的请求:
PrRd:处理器请求读一个Cache LinePrWr:处理器请求写一个Cache Line
总线对Cache Line的请求:
BusRd:总线指出有一个其他CPU核心对Cache Line要读取BusRdX:总线指出CPU核心请求写一个此核心不拥有的内存BusUpgr/BusRd(S):总线指出CPU核心请求写一个该核心拥有的内存Flush:总线指出某个Cache Line请求将数据写回主存FlushOpt:总线指出某个Cache Line要将数据发给另外一个Cache Line
图中边上的操作,/前是CPU主动发出的操作,后面是发出之后总线立刻发出的请求。
注意:WIKI上的图和他说的操作不一致。图是MESI基本版的,但是操作却是优化版的。不要再看WIKI上的图了。
比如M状态,此时CPU无论是读(PrRd)还是写(PrWr),因为Cache Line此时就是最新值,那么直接读写,不会跳转到其他状态,总线也不会报任何请求。
对于E状态,如果CPU要求读取(PrRd),那么就直接从Cache Line中读。但如果要写(PrWr),那么显然E状态要转变为M状态,此时此Cache Line内的值是新的,且没写回主存。但此时总线依旧不进行请求(因为根本没人读这块内存)。
但是对于S状态,如果CPU进行PrWr的写请求,此时需要从S状态切换到M状态(表示我有最新数据),并且总线发出BusUpgr请求,表示我这个Cache Line开始写了。并且其他所有数据都应该失效。那么所有原本位于S状态的Cache Line都需要切到I状态标识无效,直到在I状态发出PrRd或PrWr请求才从内存中读取新值。其他状态同理。
Store Buffers
MESI虽然很可靠,但是会带来更多的延迟。比如某个Cache Line在S状态,需要将自己的信息写入变为M状态。这个时候发出的BusUpgr信号会将所有S状态都变为I状态,并等待这个状态做完后再执行PrWr。这时间是非常长的。
为了降低这种延迟,为每个CPU核心增加一个Store Buffer,在每次写入值时,先将值写入Store Buffer,然后去处理其他事情。当所有失效的确认都收到,数据才从Store Buffer里提交出去。
Store Buffers有两个风险:
处理器自读自写的时候会读到旧值(因为写直接写入Store Buffers而非Cache,读却从Cache中读)。处理方法是多读一次Store Buffer(叫store-to-load forwarding或者 store forwarding)。不过这一步对程序员是透明的,我们写码时不用关心。
跨核心数据不可见:CPU核心之间的Store Buffer是互相不可见的,这意味着不同核之间仍旧会读到其他核对应Cache中的旧值。举个例子:
1 2 3 4 5 6 7 8 9 10初始: x = 0; // 在核1缓存中有效 y = 0; // 在核2缓存中有效 核1: x = 1; r1 = y; 核2: y = 1; r2 = x; 此时,核1执行 x = 1 时,塞入Store Buffer,然后继续做下一条 r1 = y。此时他根本不知道和2的y有没有塞到主存里面(因为可能核2也赛道Store Buffer里面了)。所以此时r1可能是0。 那么同时,核2执行 y = 1 时, 塞入Store Buffer,然后下一条 r2 = x,这时也可能读到x的旧值0。这样就有问题。这就是memory order要解决的一个问题。
Invalidate Queue
某个Store Buffer写入主存的时候,需要等待其他Cache Line的invalidate响应消息,等他们应答之后再继续。核心的应答是将自己对应的Cache Line标记为Invalid。但其他核可能在忙迟迟不应答。这个时候,如果发起核还在不停写Store Buffer给他写满了,那到时候就真的只能等Store Buffer写入主存后再执行指令了(不能越过Store Buffer继续执行后面指令了)。
所以为了加快invalid响应,其他核在收到invalidate消息时,会先将消息请求丢到Invalidate Queue中排队,然后立刻返回一个invalidate响应。至于自己什么时候真正处理这个Invalidate消息那是他自己后面再找时间。
这样发起核可以尽快排空Store Buffer。
但是问题在于,其他核由于没有及时做Invalidate操作,可能发起核的Store Buffer排空,所有数据都已经写入主存了,这时本核还认为自己的Cache Line是有效的,又从自己的Cache Line里面读旧值(核心只会查Cache,不会查Invalidate Queue来看他自己有没有无响应操作)。具体例子就是:
| |
这样也会有问题。这就是memory order要解决的另外一个问题。
MESI与Data Racing
注意,MESI管辖的范围非常小,他只管多个Cache之间的一致性(Cache Coherency)。而Data Racing发生在内存一致性(Memory Coherency),是发生在主存上的。MESI并管不到他。
MESI甚至对Store Buffers和Invalidate Queues没有感知。也就是说就算MESI规定了每个Cache之间的值一致性,但Store Buffers和Invalidate Queues造成的数据往主存写入的时机可能会撞车(比如两个Store Buffers同时往一个地址上写,当然由于主存所在Bus只有一条,严格意义上说往主存写的操作同一时间只能有一个。那么第一个Store Buffer往里面写入,后一个Store Buffer再写入就会覆盖掉之前的值,造成数据竞争)。
Memory Order
memory order真正在做的事情有两件:
对于同一线程的指令,防止编译器指令重排:因为编译器可能会将不想关的指令重新排列,比如:
1 2 3 4 5 6 7 8 9 10int data = 0; std::atomic<bool> ready{false}; // 生产者线程 data = 42; // 普通写 ready = true; // 假设这里没有memory order约束 // 消费者线程 while (!ready) {} // 假设这里没有memory order约束 assert(data == 42); // 可能失败!这里,生产者线程和消费者线程都可能进行指令重排。这个时候变成:
1 2 3 4 5 6 7// 生产者线程 ready = true; // 假设这里没有memory order约束 data = 42; // 普通写 // 消费者线程 assert(data == 42); // 失败! while (!ready) {}显然这里会出问题(当然生产者线程重排,消费者线程没重排也会出问题。有多种出错方式)。
所以要阻止指令重排。
对于不同线程的指令,约束Store Buffer和Invalidate Queue(也可以认为是防止硬件重排,因为现代CPU还有更多的小优化都会破坏一致性)。
真正意义上来说,memory order其实是控制内存操作顺序和跨线程可见性。
注意,memory order只会禁止重排自己线程的指令(软件和硬件上),不会影响别的线程。
那么就可以真正来看一下各个memory order到底在做什么了:
relaxed:不做任何保证,不防止指令和硬件重排。一般用于纯计数功能。release:只用在写操作上。在他之前的指令不能重排到他之后,硬件上则在执行此指令前排空Store Buffer,保证前面的写入均被其他线程可见。与acquire配对使用。acquire:只用在读操作上。在他之后的指令不能重排到他之前,硬件上则保证在执行此指令之后,刷Invalidata Queue(让release之前的所有值都在acquire处可见)。与release配对使用acq_rel:仅RMW操作使用,因为RWM即读又写,所以这个操作其实是同时做了acquire和releaseseq_cst:是acquire+release的增强版,可以同时用在读和写操作上。在原子指令写后/读前排空Store Buffer/Invalidate Queue,让原子操作在写完之后立刻可见,以及在读前可见别的线程的值。这意味着代码就是按照你写的方式执行,没有任何重排,缓存也必须及时刷新。正如其名称,这种严格一致性被称为“顺序一致性”(Sequential Consistency),是所有一致性中最严苛的,也是最昂贵的。其原始定义为:
多线程执行的结果,等同于把所有线程的操作【交错排进某一条单一的全局顺序】里逐个执行;且每个线程自己的操作,在这条全局顺序里保持它的【程序顺序】
从指令重排的角度思考memory order
任意两条不相关的读写指令都可能重排,存在四种指令重排:
| 类型 | 含义 | 示例 |
|---|---|---|
| LoadLoad | 两个读指令之间的重排 | load A; load B;重排为 LoadB; LoadA; |
| LoadStore | 读写指令重排 | LoadA; Store B; 重排为 Store B; Load A; |
| StoreStore | 写指令重排 | Store A; Store B; 重排为 Store B; Store A; |
| StoreLoad | 写读指令重排 | Store A; Load B; 重排为 Load B; Store A; |
不同架构允许不同的指令重排。
在x86上,只有StoreLoad被允许。在其他弱内存架构(ARM, RISC-V等)中可能允许其中四种。
那么也就是说,当你使用acquire/release禁止前三种重排时,在x86上几乎没代价(硬件根本不会重排)。但第四种几乎是在任何平台上都会产生代价的重排。
各种memory order约束的指令重排如下:
| memory order | 约束的重排 |
|---|---|
| relaxed | 无约束 |
| acquire | LoadLoad + LoadStore (后面的读写不能排到前面) |
| release | StoreStore + LoadStore (前面的读写不能排到后面) |
| seq_cst | 约束所有的重排(也是唯一能约束StoreaLoad的) |
再次举例为什么需要seq_cst:假设下面的例子造成的StoreLoad情况:
| |
这时只是a不能迁移到x下面,b不能迁移到y上面,但是x和y本身可以互相重排,这导致这种重排结果:
| |
甚至是这种重排结果:
| |
这就是为什么需要seq_cst,使用下面的代码会避免重排:
| |
其他杂项
互斥锁的指令重排
Herb Sutter在他关于Atomic的演讲中(见参考1)说了这样一个例子:
| |
这段代码可以被重排为:
| |
但不能被重排为:
| |
从语义上理解,是因为这里y可能是一个flag,当其他线程看到y被设置值之后,就认为x已经被设置值了。最下面的重排破坏了这个意思。
从实现上理解,在实现互斥量的时候,其实内部就用到了acquire和release操作。上面的代码其实含有如下意思:
| |
那么从memory order的角度考虑,显然x和z不能随意重排(当然真实mutex实现更复杂)。
(同时注意这里是先acquire后release,和之前的seq_cst例子不一样)